
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Reading Excel Files with Pandas read_excel() in Python

The read_excel() function is a part of the Pandas library of Python which is specifically designed for reading data from Excel files. Excel files are commonly used for storing tabular data, and the read_excel() function provides a convenient and flexible way to import this tabular data for analysis and manipulation within a Python environment. In this tutorial, we will understand how we can read an Excel file into a Pandas DataFrame by using the read_excel() function. Let’s get started.
Also Read – Exporting DataFrame to Excel File with Pandas to_excel() in Python
Syntax of Pandas read_excel() Function
The read_excel() function supports both .xls and .xlsx formats and it provides various options to customize the reading process.
Syntax:
read_excel(io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=None,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
decimal='.',
comment=None,
skipfooter=0,
convert_float=None,
mangle_dupe_cols=True,
storage_options=None)
Important Parameters:
- sheet_name: Name or index of the sheet to read.
- header: Row to use as the column names.
- names: List of column names to use.
- index_col: Column to set as index (integer or column name).
- usecols: Columns to parse (int, str, list-like, or callable).
- skiprows: Number of rows to skip at the beginning.
Using Excel File to Create a DataFrame
We have a dummy Excel file called Students.xlsx containing two sheets, one is a student and another is a teacher as shown below.
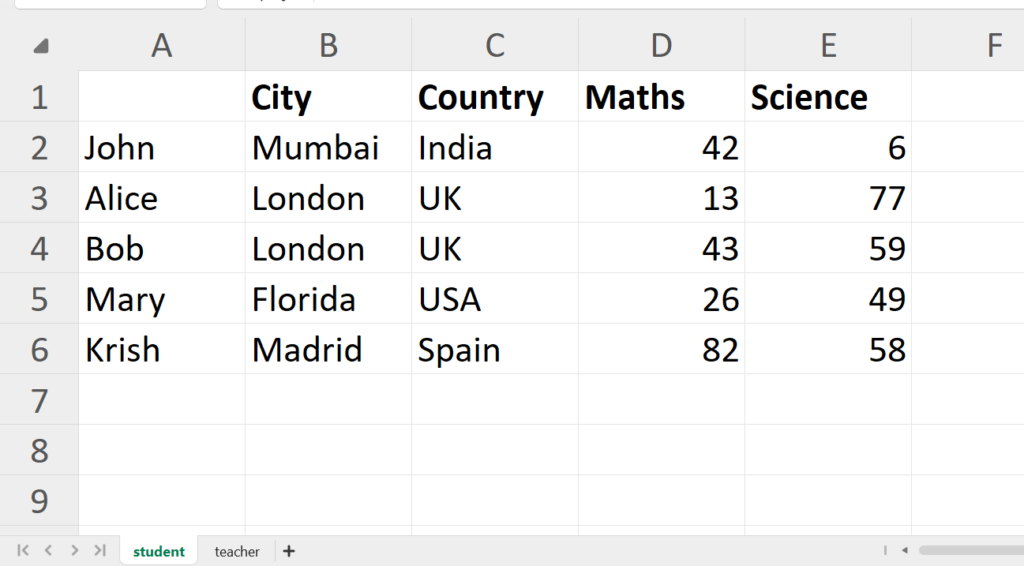
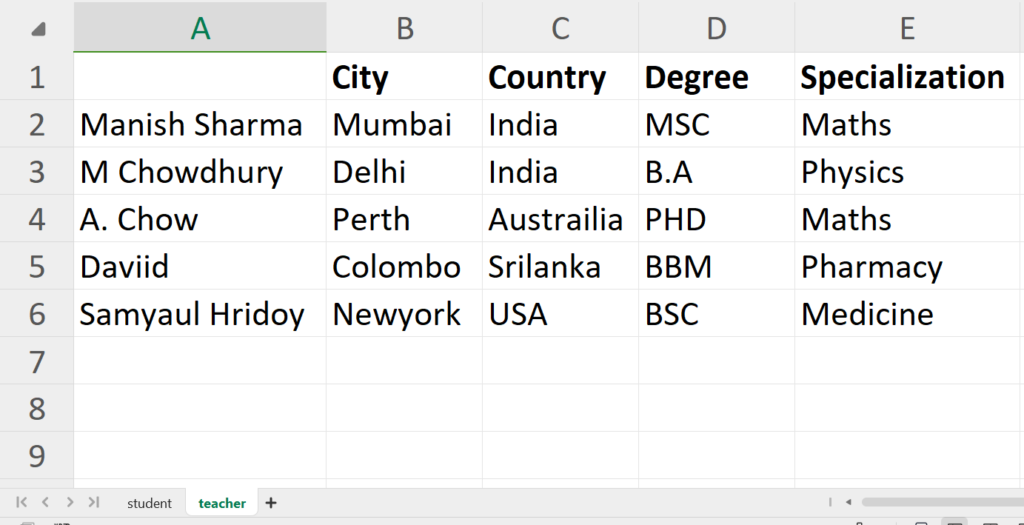
Now to read the Excel file, first we need to import the Pandas module as pd so that we can use its function read_excel() to read it.
import pandas as pd
pd.read_excel('Students.xlsx')
In the code above we have passed our Excel file name Students.xlsx as an input into the read_excel() function so that we can read our Excel file.
Output:
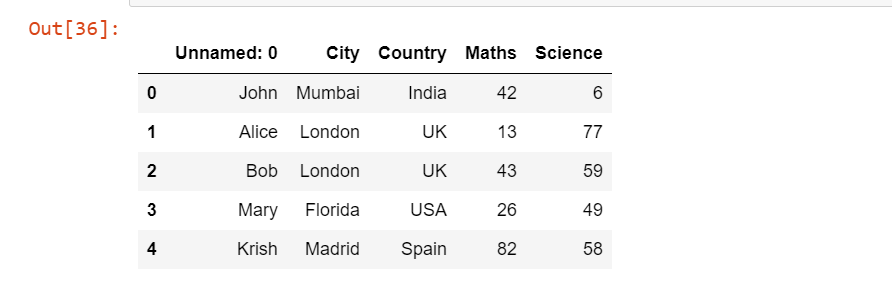
After executing the code we can see that read_excel() function successfully read the Students.xlsx file and identified that the first row is the header row. But still, there is one column where we haven’t given any kind of header name, which is considered as a Unnamed:0, which is nothing but a student name.
Setting a Column as the Index
Now suppose we want to make the ‘Unnnamed: 0’ column as an index column so that we can access the individual rows through names like “John” information or “Alice” information. To do this we can simply add one argument index_col as 0 so that the zeroth column will be considered as an index column and the zeroth column is ‘Unnamed: 0′.
pd.read_excel('Students.xlsx', index_col=0)
Output:
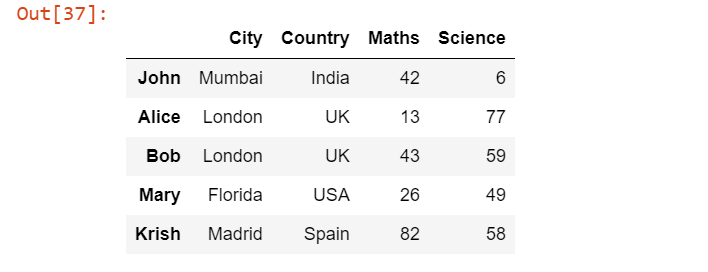
In the output, we can see the difference that all the names become index columns.
Defining a New Header
By default, the very first row or we can say the zeroth row has been considered as a header, but suppose the Excel file cannot consider the first row as a header row, in that case, we can just simply add one more argument like a header is equal to some other row.
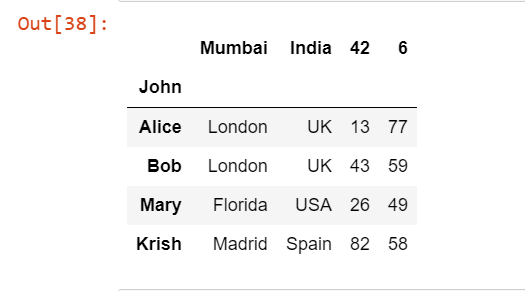
pd.read_excel('Students.xlsx', index_col=0, header=1)
In the code above we have taken the header as 1 means the 1st row will be the header now in the Excel file which was by default the zeroth row.
Output:
Reading Specific Columns
Now suppose instead of reading all those columns we want to read the first few columns only. Let’s say just the Name, City and Country column. For this, we can add one more argument usecols.
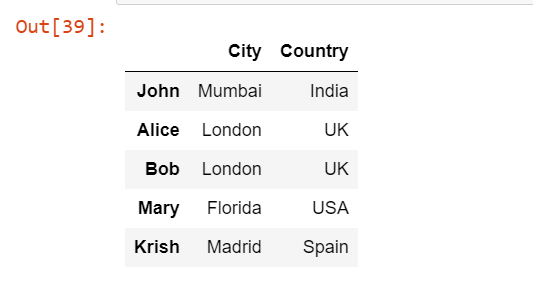
pd.read_excel('Students.xlsx', index_col=0, usecols="A:C")
We have added an argument usecols as “A:C” to the read_excel() function which will read only three columns from the start.
Output:
Changing Column Names
Now suppose we want to give the custom name to every single column, for this, we can pass an argument names. So in our case, we are just accessing the first three columns that’s why we have to give the first three column names only. If we try to name all five columns then it will throw an error.
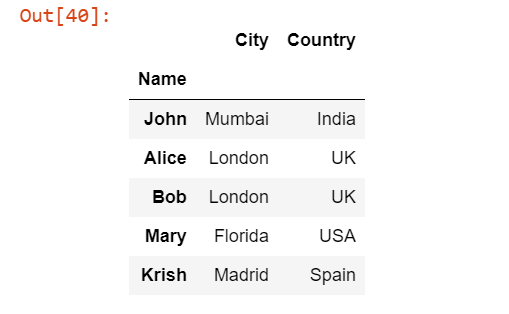
pd.read_excel('Students.xlsx', index_col=0, usecols="A:C", names=["Name","City","Country"])
We have passed a names argument as [“Name”,”City”,”Country”] into read_excel() function which will give the custom name to the first three columns as we are reading only three columns from starting.
Output:
Specifying Sheet Name for Data Extraction
Until now we have dealt with the very first sheet only whose name is student but there is a second sheet also in the Excel file Students.xlsx whose name is teacher. So to read the second sheet we need to pass the sheet_name argument as 1 and by default the sheet_name value is 0 means the first sheet.
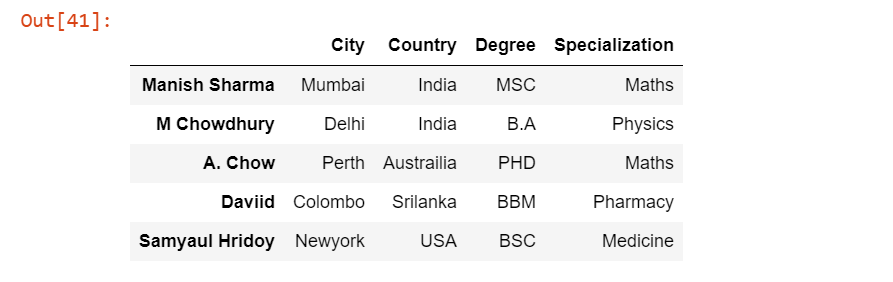
pd.read_excel('Students.xlsx', index_col=0, sheet_name=1)
Output:
Skipping Rows
Let’s say we don’t want some of the rows from our DataFrame. So for this, we can assign an integer or the list of integers to an argument skiprows.
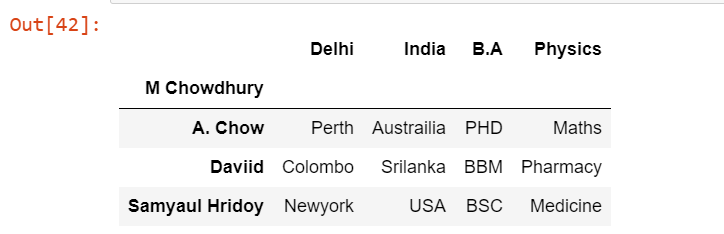
pd.read_excel('Students.xlsx', index_col=0, sheet_name='teacher', skiprows=[0,1])
We have passed skiprows as [0,1] means the first two rows from the DataFrame will be skipped.
Output:
Summary
In this article, we have learned about the Pandas read_excel() function in Python. We learned how to read Excel files into DataFrames, including techniques such as setting a column as the index, skipping rows, specifying sheet names, changing column names, and selectively reading specific columns. After reading this article, we hope you can easily read an Excel file into a Pandas DataFrame in Python.
Reference
https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html





