
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Parsing HTML in Node.js with node-html-parser

HTML (Hypertext Markup Language) is used to construct web pages and define their structure and components through various elements and tags. In Node.js, the npm node-html-parser module provides a powerful tool for HTML parsing. It simplifies interaction with HTML and lets us do tasks like data extraction, web scraping, content manipulation, etc.
In this article, we will learn how to use the node-html-parser for HTML parsing in Node.js applications.
How HTML Parser Works?
HTML parser works by analyzing the structure of HTML documents according to the rules and specifications of the HTML language. The general operation of HTML parsers is as follows:
Step 1: Tokenization – The HTML parser begins by tokenizing the input HTML content. This process divides individual elements into tokens.
Step 2: Parsing – Once the token is created then the parser starts to parse the token and build a tree, known as the Document Object Model (DOM). Each node in the tree corresponds to an HTML element representing the hierarchical structure of the HTML page
Step 3: Manipulation and Traversal – After the DOM tree is built, we can access or modify its nodes by traversing the tree.
Since HTML parsers allow us to interpret, analyze, and alter HTML pages, they become essential for web development, mainly for operations like data extraction, content rendering, web scraping, or other applications.
Introducing node-html-parser
node-html-parser is a lightweight and fast HTML parser that provides us with a simple API for parsing and manipulating HTML in Node.js.
Key Features:
- Fast HTML Parser – It is a fast HTML parser so our Next.js application performs well even when we process big HTML documents.
- Easy to Use –This module offers a simple API, making it easy to parse and manipulate HTML elements without knowing any advanced concepts. Best for beginners.
- No Dependencies – It is a standalone library with no external dependencies so it is easy to install and can use in any Node.js project.
- Simplified DOM Tree – It generates a simplified DOM tree that allows us to easily navigate and manipulate HTML elements.
- Element Query Support: It also allows us to find elements using query selector methods like querySelector and querySelectorAll.
Installation:
We can install node-html-parser using NPM by running the below command:
npm install node-html-parser
Parsing HTML in Node.js Using node-html-parser
Step 1: Initializing your Node.js Project – We can initialize our Node.js project by navigating to your project directory in your terminal and running the following command.
npm init -y
Step 2: Installation of Package – Install the module by running the following command in your terminal.
npm install node-html-parser
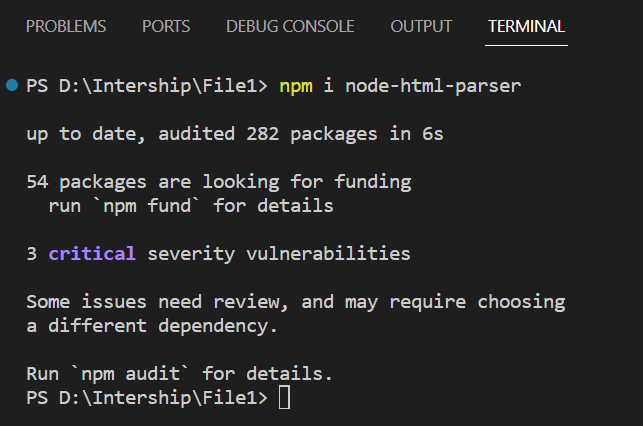
Step 3: Importing the Package – After installing the module, you can import it into your script to use the functionality given by the package.
const { parse } = require('node-html-parser');
Step 4: Here’s an example using npm node-html-parser to parse HTML string.
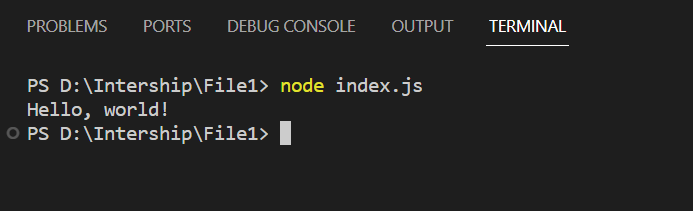
const { parse } = require('node-html-parser');
const htmlString = '<div><p>Hello, world!</p></div>';
const root = parse(htmlString);
console.log(root.querySelector('p').text);
Firstly, we import the parse function from the node-html-parser module and define an HTML string (“Hello, world!“) containing a <div> element with a nested <p> element. Then we use the parse function to parse the HTML string and create a DOM tree representation of the HTML content then use the querySelector method on the parsed root element ( <div>) to select the first <p> element within it and access the text property of the selected <p> element to retrieve its text content. Finally, it logs the text content to the console.
Output:
Uses of HTML Parser
Below are some examples of why the HTML parser is useful.
1. Analyzing the Structure of the DOM Tree
We can use it to parse HTML and access the structure using the first child node of the root element.
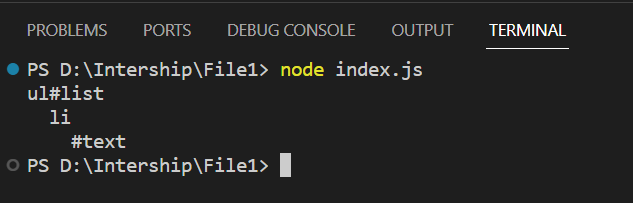
import { parse } from 'node-html-parser';
const root = parse('<ul id="list"><li>Hello World</li></ul>');
console.log(root.firstChild.structure);
Firstly we import the parse function from the npm node-html-parser module. The parse function will parse HTML strings and create a DOM tree representation (root) of the HTML content. Then we log the structure of the DOM tree starting from the first child of the root node. The structure shows the hierarchy of the elements in the HTML content.
Output:
2. Modifying DOM Content
We can also use this library to modify the content of the root node.
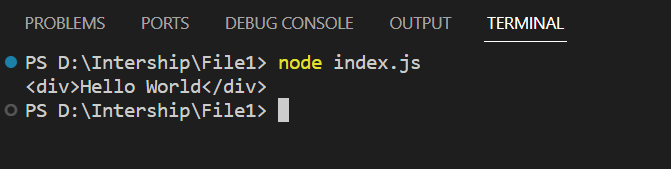
import { parse } from 'node-html-parser';
const root = parse('<div></div>');
root.set_content('<div>Hello World</div>');
console.log(root.toString());
We set the content of the root node to <div>Hello World</div>. Here, the root.toString() function converts the modified DOM tree (root) back to an HTML string representation.
Output:
Conclusion
In conclusion, node-html-parser is a powerful and versatile library for parsing and manipulating HTML documents in Node.js applications. Throughout this article, we explored the features and capabilities of Node HTML Parser, including its ability to parse HTML strings, traverse the DOM tree, extract specific elements, and modify attributes and content.
Continue Reading:
Reference
https://www.npmjs.com/package/node-html-parser





