
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Top 5 Python Libraries for Machine Learning and Data Science

Python has become one of the most popular programming languages nowadays. There are various reasons behind its popularity. A few of those are listed below:
- Python syntax is similar to the English language which makes it easy to learn and remember.
- Python provides portability.
- Python provides a vast range of robust libraries which makes it easy to fit every solution.
When it comes to Data Science and Machine Learning field, Python is the priority. Data Science and Machine Learning are the future of technology, so is the Python. We are constantly dealing with features built on AI and Machine learning without knowing for example Google Voice Search or Google Photos Netflix, Uber, Instacart, amazon Recommendations. Nowadays most of the big organizations are investing in AI and ML. As a python developer, you need to know the top libraries python provides for AI, ML, and Data Science. Let’s move to top 5 python libraries and overview.
- Tensor Flow
- Numpy
- Pandas
- Matplotlib
- SciKit-Learn
- Keras
1. TensorFlow:
This powerful python library is developed by Google in collaboration with Brain Team. Google Machine Learning applications have many features on TensorFlow. Neural networks can be easily expressed as computational graphs so TensorFlow can implement it using tensor operations. Tensors are N-dimensional matrices that represent data. It performs linear algebra operations quickly using the XLA technique. You have to install the TensorFlow library first for python. Then you can perform operations on arrays. Below is the simple code snippet to show the multiplication of two arrays. First, you have to initialize two variables for array storage using Constant() and pass the array as an argument you wish to perform calculations.
import tensorflow as tf
arr1 = tf.constant([10,20,30,40]) # array 1 contains 10,20,30,40
arr2 = tf.constant([1,2,3,4]) # array 2 contains 1,2,3,4
# now multiply both arrays using tensorflow
multiplyOutput = tf.multiply(arr1, arr2)
#now if you want to display the result you have to initialize a session
# Intialize the Session
sessnew = tf.Session()
# Now print the multiplyOutput result
print(sessnew.run(multiplyOutput))
# Now you have to close the session
sessnew.close()
Output:
[10,40,90,160]
We can feed data using TensorFlow. Then some plotting can be performed. Then we can feed data into the machine for modeling. The best thing is that We can visualize each part of the graph using TensorFlow which is not available in Numpy or SciKit. Google Voice Search or Google Photos are the applications of TensorFlow.
2. Numpy:
Numpy is a popular python library and a basic building block of machine learning. It handles matrix computations. TensorFlow and other python libraries use Numpy internally so Numpy is mandatory to learn. Numpy is Array Interface, one dimensional or N-dimensional. Numpy is used to express images, sound, videos, or any other binary raw streams in form of an N-dimensional array of real numbers.
Below is the code snippet to declare an empty Numpy array:
import numpy as npy
arr_one=npy.array([])
type(arr_one)
Output:
numpy.ndarray
You can use below code to create one dimensional array:
array_onedim = npy.array([1, 2, 3, 4, 5])
print(array_onedim.ndim) # ndim attribute displays the dimension of an array
print(array_onedim.size) # size attribute displays the length of the array
Output:
1
5
There is one more way to create an array using arange(). Array once created, can be reshaped to other dimensions as well. For example, you have a one-dimensional array of 10 elements, it can be converted into a 2-dimensional array i.e. 5 elements in one row and another 5 elements in the second row. This is how expanding is done in a NumPy array. This python library is useful in real-time calculations where few Data is missing but still, calculations need to be performed so we expand existing data and proceed.
print(npy.arange(2, 12))
npy.arange(2,12).reshape(2, 5) # 1 dimensional array reshaped into 2 dimensional.
Output:
[2 3 4 5 6 7 8 9 10 11]
array([[2, 3, 4 ,5 ,6],
[7, 8, 9, 10, 11]])
Now reshaped array can be flattened as well. It means we are again converting it back to a one-dimensional array. The below code is a sample for it.
npy.arange(2,12).reshape(2, 5).ravel()
Output:
array([2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
Since Numpy works on Matrix, it is easy for a machine to understand. But, for a human, it becomes a little complex, so the answer is the Pandas.
3. Pandas:
This python library is the most popular for data manipulation and analysis. Before you start training machines in ML, the data set should be prepared. So pandas are useful in data extraction and manipulation like filtering, grouping, combining, filling out missing data. Pandas is not directly linked with ML but, is essential for data preparation before ML. Data is stored in form of Data Frames in this python library.
A 2-dimensional labeled data structure is called a Data Frame. Let’s see how we can create a data frame in pandas:
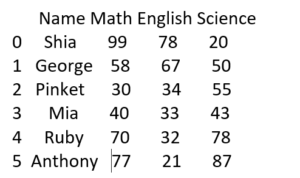
#Storing names of students and their respective marks in different subjects
import pandas as pd
name = ["Shia", "George", "Pinket", "Mia", "Ruby", "Anthony"]
math = [99, 58, 30, 40, 70, 77]
english = [78, 67, 34, 33, 32, 21]
science = [20, 50, 55, 43, 78, 87]
# Now creating a result data frame which will hold all data in tabular form.
result = pd.DataFrame({
"Name”: name,
"Math”: math,
"English": english,
"Science”: science
})
print (result)
Output will be display as below image.
Once your data set is ready, either you can analyze it more by using graphs, charts or you can build a model for Machine. So for data visualization, we have Matplotlib and for a model building, we have Scikit-Learn python libraries.
4. Matplotlib:
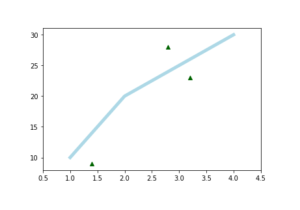
This python library is for Data Visualization. We can create a bar chart, pie chart, scattered graph, histogram which are used to analyze trends, patterns for decision making. The decision can be taken by a business based on data set visualization. For example, a pie chart for a product sale can display a percentage of categories like men, women, and elderly people. So a business can see that their product is popular among men or women category. Below is the sample code to generate a scatter plot.
import matplotlib.pyplot as pt
pt.plot([1, 2, 3, 4], [10, 20, 25, 30], color='lightblue', linewidth=5)
pt.scatter([0.3, 3.2, 1.4, 2.8], [11, 23, 9, 28], color='darkgreen', marker='^')
pt.xlim(0.5, 4.5)
print(pt.show())
Output will be display as below image.
5. SciKit-Learn:
This python library is for deep Machine learning that provides Supervised and Unsupervised Learning Algorithms. This library majorly focused on model building. This library has many features for model building. For example, if you are building a linear model, you can import LogisticRegression from sklearn.linear_model. There are many others like DecisionTreeClassifier from sklearn.tree, RandomForestClassifier from sklearn.ensemble which are handy in this python library.
Bonus – Keras:
It is a very popular Machine Learning library for Python. This neural network API is capable of running on top of TensorFlow, CNTK, or Theano. Keras can run easily on both CPU and GPU. Keras is good for ML beginners to build and design a Neural Network. Easy and fast prototyping is provided by Keras python library. We are not aware but we use Keras every day through popular programs e.g. Netflix, Uber, Yelp, Instacart, Zocdoc, Square. Keras is easy to debug as it is a completely Python-based framework.
Python also provides many ML libraries including SciPy, PyTorch, Theano, LightGBM, Eli5, and NLTK other than the top libraries which we have discussed here. If you are into Data Science or Machine Learning area, the above list of best Python libraries is going to help you to start. Python with Data Science and ML is an interesting concept. I hope this article will invoke your interest in Python. We need to deep dive a little more into Data Science before moving to ML. I am sure you want to know more about Python libraries in the next articles.
Keep exploring and learning!





