
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Read_CSV Delimiters Using Pandas

Python can be such a blessing for analyzing data, but it ain’t a single source repository of all information there is. This information extracted in the form of datasets is to be sourced from elsewhere and is to be transferred into Python for making the analysis happen. But not all data are neat and tidy! There are instances in which a tabulation might be compressed together with the sophisticated approach of deploying delimiters.
Delimiters are stripped-down equivalents of the lines or borders that separate data in each cell of a tabulation when it is converted into a ‘.txt’ or ‘.csv’ or other equivalent formats that don’t encourage the formatting gimmicks.
These delimiters would serve as references to the program which runs it to differentiate the data from one another across the rows and throughout the columns. This article aims to demonstrate the technique used to read data with different types of delimiters. Let’s get started!
Types of Delimiters:
The most commonly used is a comma (,). Thusly the file with entries separated by commas, have the file extension as ‘.csv’ (Comma Separated Values). Following is the list of other commonly used delimiters,
- Space ( )
- Colon (:)
- Semicolon (;)
- Underscore (_)
- Vertical bar (|)
- Tab ( )
Reading Files with Delimiters Using Pandas:
As always one shall start by importing the ‘Pandas’ library into the active Python window by typing,
import pandas as pd
Hit the ENTER key & it takes a few moments for Python to load the ‘Pandas’ library. Once the library is loaded, the arrowheads shall appear in the new line too!
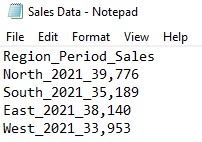
Now that the library is loaded let’s consider the following file in which the entries are separated by an underscore.
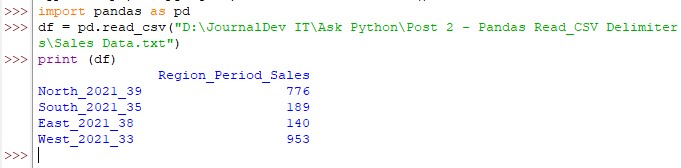
Here’s what the data shall look like if one doesn’t specify the type of delimiter used.
For loading & visualizing the above data as a tabulation, one needs to use the read_csv() command whose syntax is given below,
df = pd.read_csv(“filename.txt”,delimiter=”x”)
where,
- df – dataframe
- filename.txt – name of the text file that is to be imported.
- x – type of delimiter used in the .csv file to be stated.
- “\t” – tab
- “,” – comma
- “ “ – space
- “:” – colon
- “;” – semicolon
- “|” – vertical bar
- “_” – underscore
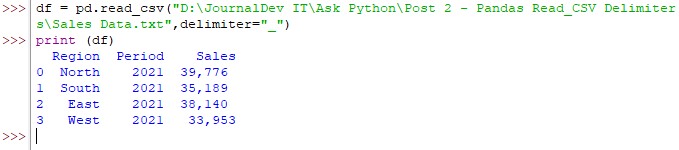
Applying the syntax to the above data results in the following,
df = pd.read_csv(“Sales Data.txt”,delmiter =”_”)
Once the above code is typed, one shall hit ENTER & if the arrowheads appear in the new line means that there are no errors. Then type the following to view the data.
print (df)
But what if to make things worse, the extracted data contains not one but a handful of delimiters? Python has a way around even in this situation!
The following data shall be used for demonstrating it.
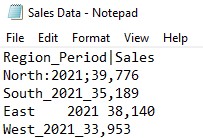
One shall type all the delimiters used within the regular single-quoted square bracket expression ‘[ ]’ such as,
df = pd.read_csv(“Sales Data.txt”,delmiter =’[_\t ;|:]’)
Hit ENTER once done & then witness the magic using the print() command as shown below.
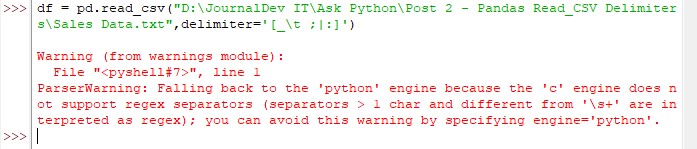
Oopsie! There seems to be a conflict in understanding these delimiters by Python. This error can be solved by the inclusion of an additional stipulation in the code as shown below.
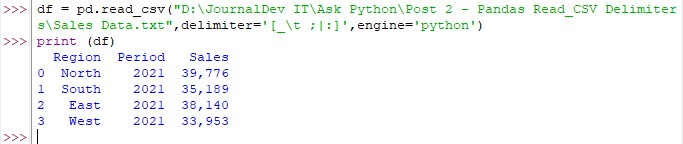
df = pd.read_csv(“Sales Data.txt”,delmiter =’[_\t ;|:]’,engine=’python’)
Run the code again with this inclusion & witness the magic – now for real!
Conclusion:
Now that we have reached the end of this article, hope it has elaborated on the usage of different delimiters that could be deployed within Pandas. Here’s another article which details how to read CSV files with Headers using Pandas in Python. There are numerous other enjoyable & equally informative articles in AskPython that might be of great help to those who are in looking to level up in Python. Ciao!Read_CSV Delimiters Using Pandas






