
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Scraping Amazon Product Data using Python BeautifulSoup
Beautiful Soup is one of the most popular Python libraries to extract data from HTML/XML files. Web Scraping is the way to download web pages as HTML and then parse it to find out the information we need through programs.
In this tutorial, we will learn how to scrape the Amazon product page and find the product name and pricing information. We need to perform the following steps:
- Download the Amazon product page as HTML using the requests library
- Find the HTML elements and their id/classes for the required information
- Use the BeautifulSoup parser to extract the information we need
Installing Required Libraries
We have to install BeautifulSoup, lxml, and requests library for this project.
$ pip install beautifulsoup4
$ pip install lxml
$ pip install requests
Find HTML tag and id/class
I am trying to extract the product name and price for this page: https://www.amazon.com/dp/B0B3BVWJ6Y/
I am using Chrome inspect element to find out the HTML tags and their id/class for product name and price.
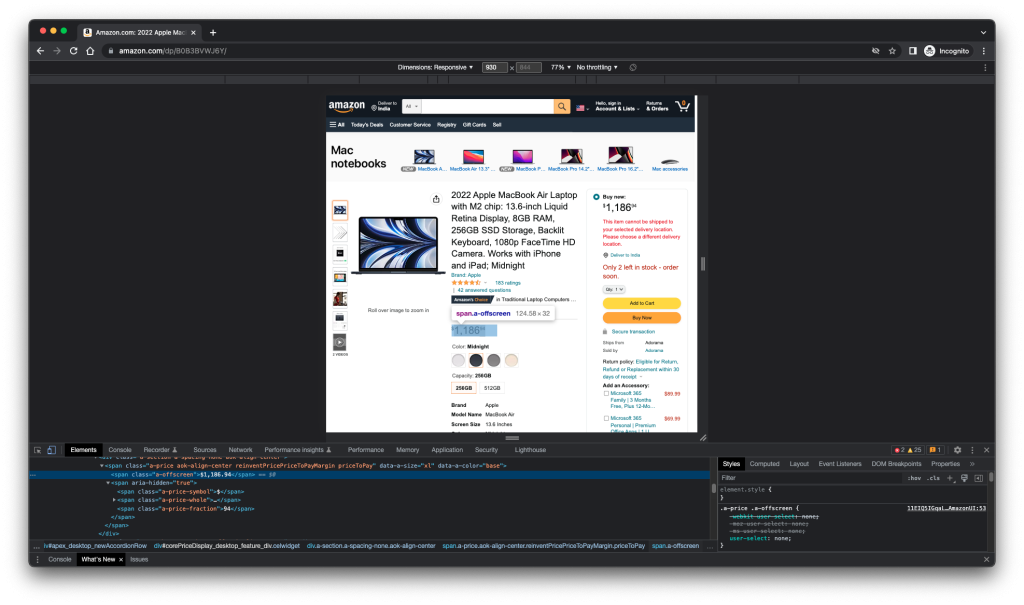
The product name is present in the “span” element with the id “productTitle“. Similarly, pricing information is present in the “span” element “a-offscreen” class.
Python Code to Scrape Amazon Product Data
The first step is to import the required libraries.
from bs4 import BeautifulSoup
import requests
The next step is to download the webpage using requests library.
webpage = requests.get(URL, headers=HEADERS)
Then we create the BeautifulSoup object with the content and the appropriate parser name.
soup = BeautifulSoup(webpage.content, "lxml")
Then, we use the find() method to extract the information from the webpage content.
soup.find("span", attrs={"id": 'productTitle'}) # for product name
soup.find("span", attrs={'class': 'a-offscreen'}) # for product price
That’s the essential part of the code. Now, let’s look at the complete program and run it.
from bs4 import BeautifulSoup
import requests
URL = 'https://www.amazon.com/dp/B0B3BVWJ6Y/'
HEADERS = ({
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 44.0.2403.157 Safari / 537.36',
'Accept-Language': 'en-US, en;q=0.5'})
webpage = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(webpage.content, "lxml")
product_name = ''
product_price = ''
try:
product_title = soup.find("span",
attrs={"id": 'productTitle'})
product_name = product_title.string.strip().replace(',', '')
except AttributeError:
product_name = "NA"
try:
product_price = soup.find("span", attrs={'class': 'a-offscreen'}).string.strip().replace(',', '')
except AttributeError:
product_price = "NA"
print("product Title = ", product_name)
print("product Price = ", product_price)
Output:
product Title = 2022 Apple MacBook Air Laptop with M2 chip: 13.6-inch Liquid Retina Display 8GB RAM 256GB SSD Storage Backlit Keyboard 1080p FaceTime HD Camera. Works with iPhone and iPad; Midnight
product Price = $1186.94
Issues and Workaround
1. Change in webpage HTML elements
Our program depends on the HTML content sent by Amazon. So, if they make any changes to the HTML elements we are using, we will also have to change our program accordingly. We can move the HTML elements information to a property file so that we don’t need to change Python code. We can change the properties accordingly and our code will start working again.
2. Requests Blocking and Proxies
If you will run the web scraping code for a lot of pages, there is a high chance your ISP or the target website will block you. You can mitigate this scenario by using proxy servers or acquiring datasets from third-party tools. For example, you can get LinkedIn datasets for your project if it’s related to LinkedIn data analytics.
Conclusion
We learned the basics of web scraping in Python. The possible issues we can face and how to handle them or utilize the third-party tools.
Resources





