
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Web Scrapping With Node.js

Web scraping is a technique in which we extract information from websites by parsing the HTML document of the web page. You can perform web scrapping in multiple ways, in this tutorial, we will be showing you how to build a web scraper using Node.js to extract information from websites. For reference, we will use our own website to scrape the content.
prerequistics
We will use the following tools:
- Node.js
- Scrapestack credentials.
- Request
- Cheerio
The request is a node module to make HTTP calls. Cheerio is a node module that helps us to traverse the DOM of an HTML document. Scrapestack is a service to scrape any website or web application in the world, for FREE!
Why Scrapestack
You might be wondering why to use a third-party service when we can just get the HTML document of any page by making HTTP calls? Because we can’t, there are many websites that implement captcha to block bots to crawl their pages and there are many single-page apps that load after you make the HTTP call. In these scenarios, service like Scrapestack helps us to forget about the hassle of crawling, we can make a simple API call and get the HTML document. Simple as that.
In order to get the credentials, create your free account on Scrapestack.
Once your account is created, you should get your API access key. Keep it safe. Let’s move towards building our application.
The App
Create a new directory and initialize Node project.
mkdir demoProject && cd demoProject
npm init --y
Let’s install our dependencies.
npm i --S request cheerio
Once the dependencies are installed, let’s go ahead and create our server.
Here is our code to extract all titles from the articles page.
const request = require("request");
const key = "YOUR API ACCESS KEY";
const cheerio = require('cheerio');
var options = {
method: 'GET',
url: 'https://api.scrapestack.com/scrape',
qs: {
access_key: key,
url: 'https://codeforgeek.com/articles/'
}
};
request(options, function (error, response, body) {
if (error) {
console.log('error occurred during scrapestack api call');
return;
}
if(body) {
const $ = cheerio.load(body);
let titles = $('.section__articleList .article__content .article__title').toArray();
titles.forEach((singleTitle) => {
console.log(singleTitle.children[0].data);
})
}
});
When you run the code, you should see the output like this.
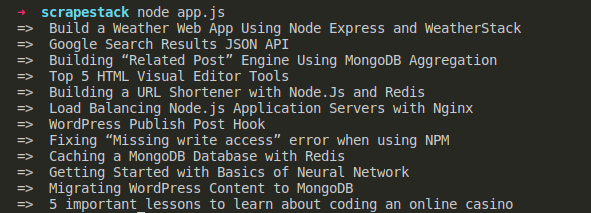
So how did we achieve it? have you noticed this code?
let titles = $('.section__articleList .article__content .article__title').toArray();
This is where Cheerio does its magic, we can traverse through HTML DOM trees similarly how we do in chrome debugger. I visited the dom tree using a chrome inspector and copied the class name.
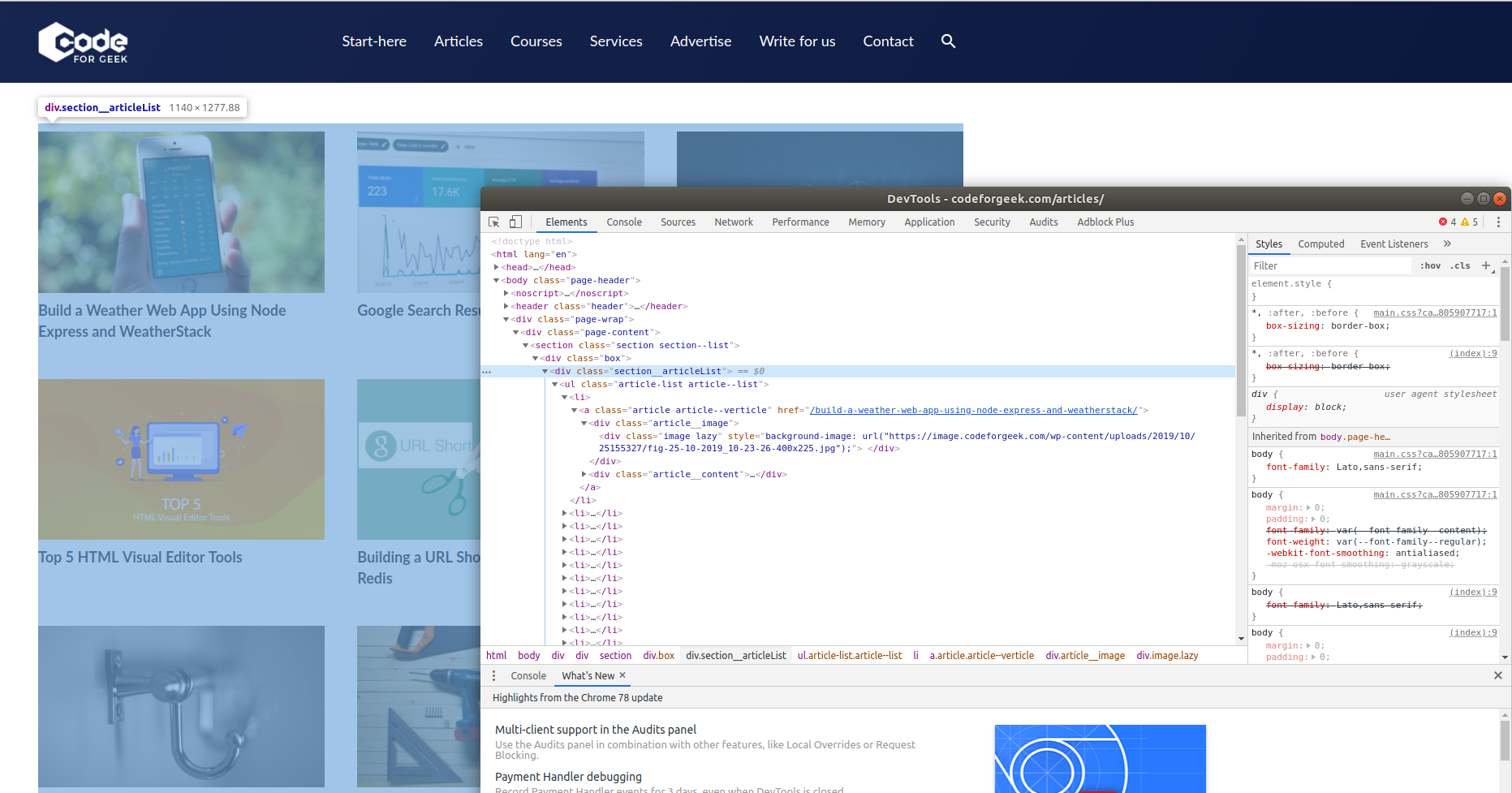
You can do a similar thing and extract almost any data you want from any websites in the world.
Conclusion
Web scrapping is still used by various companies to gather data to train their algorithms, generate a vast amount of feedback, etc. I hope with this article, you have got a glimpse of what Web scrapping is and how you can achieve it using Node.js.





