
New to Rust? Grab our free Rust for Beginners eBook Get it free →
How to Setup Multi Node Multi Broker Kafka Cluster in AWS

Apache Kafka is a distributed streaming platform used by 100’s of companies in the production environment. Kafka, in a nutshell, allows us to do three important tasks:
- Publish and subscribe to streams of data.
- Store streams of data.
- Process streams of data.
With these capabilities, we can use Kafka in a various situation such as real-time streaming, stream storage, message queue etc.
In this article, we are going to set up multi-broker Kafka in Amazon EC2. You can replicate these steps in any machine running Ubuntu.
What you’ll need
We need the following:
- 3 EC2 Instance running Ubuntu.
- Zookeeper running on each instance.
We have already covered the setup and configuration of Zookeeper in Amazon EC2 instance. Click here to read the article.
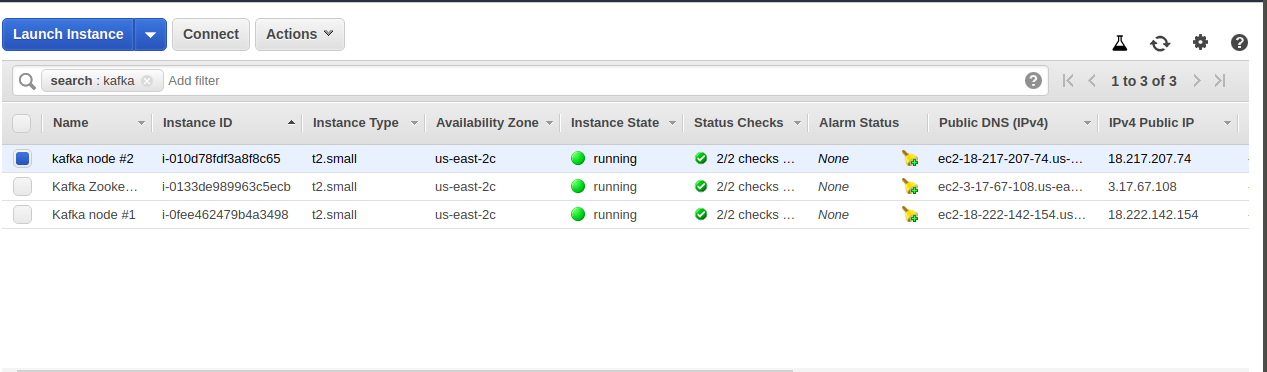
Creating EC2 Instances
Create 3 EC2 Instances of type t2.small if you are just learning or setting up a test environment. For production, go with the instance with the RAM of size 6 to 8 GB. You need good RAM to handle Java virtual machine heap requirements.
I am using Ubuntu 16.04 for the tutorial.
You need to change the security group of each instance and allow the port range 2888-3888 and port 2181.
You can change the port number if you would like to use different ports for your setup. I am going with this one.
Once you have your EC2 instance running, we can begin our setup.
Setting up Kafka
Log in to each EC2 Instance and update the packages.
$ sudo apt-get update
Then repeat the following steps on each of the instances.
1: Download the Kafka latest build.
$ wget http://mirrors.estointernet.in/apache/kafka/2.1.0/kafka_2.11-2.1.0.tgz
2: Extract the Kafka tar file.
$ tar xzf kafka_2.11-2.1.0.tgz
Now, we need to configure each server. First, run the zookeeper in each server. Make sure you have read this article and configured the zookeeper server.
Assuming you have started the Zookeeper in each instance. Let’s configure Kafka.
Switch to the Kafka folder and open the config file.
$ vi config/server.properties
On the first server, add this configuration.
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=10
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
advertised.host.name=
log.dirs=/tmp/kafka-logs
# add all 3 zookeeper instances ip here
zookeeper.connect=:2181,
zookeeper.connection.timeout.ms=6000
On the second server, add this configuration.
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=20
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
advertised.host.name=
log.dirs=/tmp/kafka-logs
# add all 3 zookeeper instances ip here
zookeeper.connect=:2181,
zookeeper.connection.timeout.ms=6000
On the third server, add this configuration.
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=30
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
advertised.host.name=
log.dirs=/tmp/kafka-logs
# add all 3 zookeeper instances ip here
zookeeper.connect=:2181,
zookeeper.connection.timeout.ms=6000
Save the config files.
Now it’s time to start Kafka on each instance.
Repeat this command on each server after switching to the Kafka server folder.
$ bin/kafka-server-start.sh config/server.properties
This is it. You have configured the multi-broker Kafka.
Testing the setup
In order to test the setup, you can do the following:
On the first machine, produce some messages on the test topic. You can use this command.
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
Type some messages
On the second machine, consume those messages.
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
You should be receiving the messages you have typed in the producer command.
Congratulations! You have set up your Multi broker Multi-Node Kafka cluster.
Conclusion
We have successfully set up the Kafka cluster with 3 Node and 3 brokers. This setup can work on production server as well if configured correctly.
This article is a part of a series, check out other articles here:
1: What is Kafka
2: Setting Up Zookeeper Cluster for Kafka in AWS EC2
3: Setting up Multi-Broker Kafka in AWS EC2
4: Setting up Authentication in Multi-broker Kafka cluster in AWS EC2
5: Setting up Kafka management for Kafka cluster
6: Capacity Estimation for Kafka Cluster in production
7: Performance testing Kafka cluster





