
New to Rust? Grab our free Rust for Beginners eBook Get it free →
3 Ways to Concatenate Two or More Pandas DataFrames

Manipulating data is a task we perform often when it comes to working data sets. To make working with these complex data sets easier for us, Python’s Pandas library provides us with many functions and features that are easy to understand and implement. Moreover, it is also crucial to visualize our data to better understand it and using Pandas DataFrames visualization has never been easier! In this article, we’ll explore various methods of effectively concatenating DataFrames using Pandas with some supporting examples.
What is DataFrame Concatenation and Why Do We Need It?
While working with Pandas we may have multiple DataFrames in a single file that we want to combine and create a new DataFrame. Here’s where concatenation comes into play. Concatenation technically means combining two or more things, in our case, combining two or more DataFrames. There are two primary ways in which DataFrames can be combined, horizontally and vertically. This helps us maintain our data concisely in lesser DataFrames, rather than leaving it scattered as multiple ones.
Concatenating DataFrames Using concat() Function
Before we look at how we can concatenate DataFrames, we must first install Pandas into our virtual environment or on our system.
The command to install Pandas is as follows:
pip install pandas
After installation, we can use Pandas by importing it into our File. This library provides concat() function by which we can concatenate DataFrames.
Pandas concat() Function
The concat() function is an in-built function provided by Pandas for concatenating multiple DataFrames. It allows us to efficiently combine DataFrames both horizontally and vertically.
Syntax:
pandas.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, verify_integrity=False, sort=False, copy=None)
- objs: Signifies the DataFrames to be concatenated. There should be a minimum of two DataFrames.
- axis: It has a default value of 0, which indicates vertical (row-wise) concatenation. Can be changed to axis=1, which indicates concatenation should take place horizontally (column-wise).
- join: Indicates how the indices on the other axis should be handled.
- ignore_index: Allows you to control whether the original index values of the DataFrames should be retained in the resulting DataFrame, or whether they should be changed to new indices.
- keys: Construct hierarchical indices other than the already existing indices, in the new DataFrame.
- levels: Allows you to create different levels of MultiIndex.
- verify_integrity: Used to check for duplicates in the new DataFrame.
- sort: Sort of non-concatenating axis is not aligned.
- copy: Used to prevent data from being copied unnecessarily.
Ways to concatenate DataFrames using concat() function are:
- Using concat() for row-wise concatenation
- Using concat() for column-wise concatenation
- Concatenating DataFrames with different columns.
Let us understand each of these methods in detail with some examples.
1. Using concat() for Row-Wise Concatenation
We use row-wise (vertical) concatenation when we have two DataFrames with the same column names and different values that need to be combined. The DataFrames are combined vertically in this case. Let’s look at an example of how we can use the concat() function to concatenate two DataFrames row-wise.
Example:
import pandas as pd
data1 = {'Name': ['Tony', 'Natasha', 'Steve'],
'Marks': ['89', '93', '72']}
data2 = {'Name': ['Bruce', 'Clark', 'Diana'],
'Marks': ['91', '87', '98']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
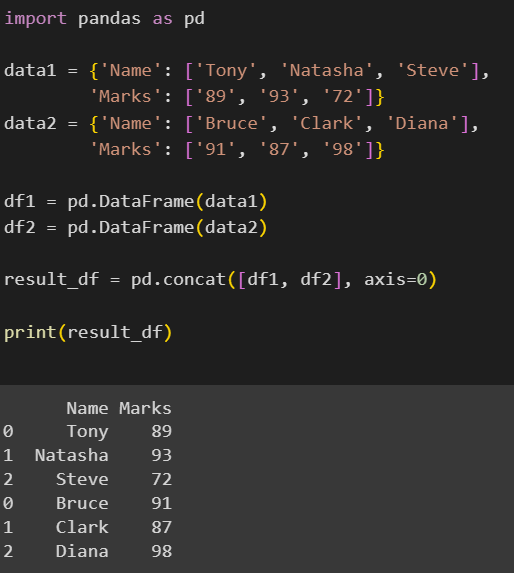
result_df = pd.concat([df1, df2], axis=0)
print(result_df)
Here, we have two separate DataFrames, df1 and df2 containing the fields Name and Marks. We have concatenated these DataFrames using the concat() method, axis=0 indicates that the DataFrames have to be concatenated row-wise. The output is a single DataFrame containing 6 rows.
Output:
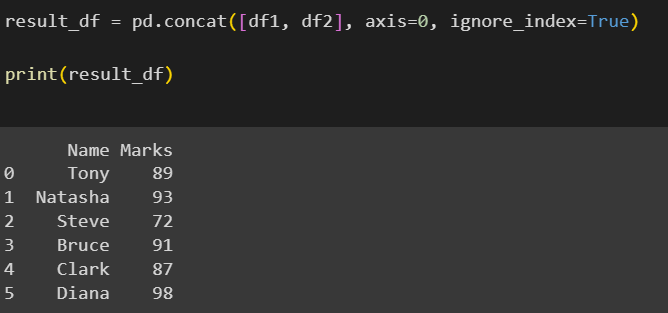
We can set an argument ignore_index=True to make the indices of the second DataFrame consecutive to those of the first DataFrame.
Output (using ignore_index=True):
2. Using concat() for Column-Wise Concatenation
Column-wise (horizontal) concatenation works similarly to row-wise concatenation, the only difference is setting axis=1 while using concat() for column-wise concatenation. We mostly use this type of concatenation when our DataFrames contain different column names. Let us look at an example of how we can perform column-wise concatenation using concat().
Example:
import pandas as pd
data1 = {'Name': ['Tony', 'Natasha', 'Steve'],
'Marks': ['89', '93', '72']}
data2 = {'Rollno': ['21', '39', '50'],
'Grade': ['B', 'A', 'C']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
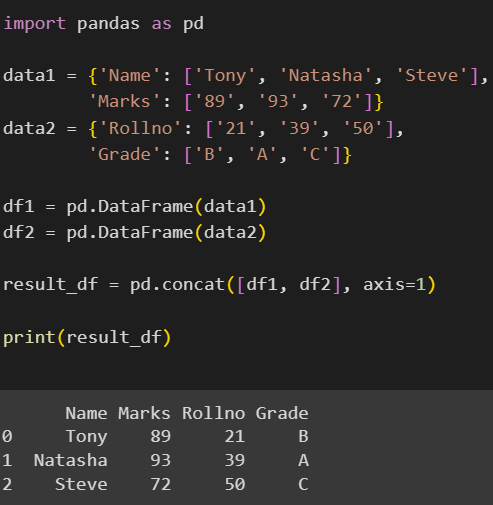
result_df = pd.concat([df1, df2], axis=1)
print(result_df)
Here, we have two DataFrames df1 and df2 with different fields. We have concatenated both these DataFrames using concat() and axis=1 indicates that concatenation must be done column-wise. The output is a single DataFrame containing all the columns and their values from both DataFrames.
Output:
3. Concatenating DataFrames with Different Columns
There are cases while using concat() where there may not be values that correspond to a certain field in the DataFrame we are concatenating with. Some fields may have missing data, these values are represented using NaN (Not A Number). Let us understand with an example, where we will concatenate two DataFrames with different column names row-wise, instead of concatenating it column-wise.
Example:
import pandas as pd
data1 = {'Name': ['Tony', 'Natasha', 'Steve'],
'Marks': ['89', '93', '72']}
data2 = {'Name': ['Bruce', 'Clark', 'Diana'],
'Grade': ['B', 'A', 'C']}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
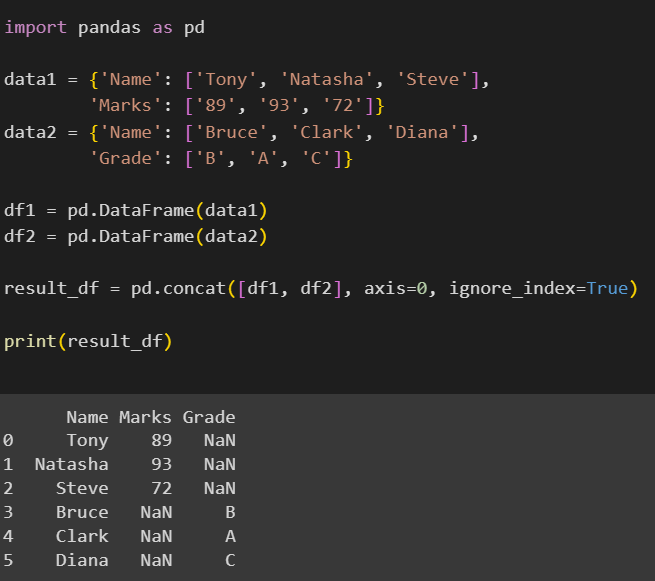
result_df = pd.concat([df1, df2], axis=0, ignore_index=True)
print(result_df)
Here, we have two DataFrames df1 and df2 which have the Name field in common. Therefore, The Name column will have 6 rows. Since df1 doesn’t contain a Grade column, the values of Grade from df1 will be represented with NaN, similarly, since df2 doesn’t contain a Marks column, the values of Marks from df2 will be represented with NaN.
Output:
Conclusion
Concatenating multiple DataFrames is a vital operation when it comes to working in Pandas. Using the concat() method we can easily combine DataFrames, whether it be horizontally or vertically. Even with different column names, concat() efficiently handles missing data using NaN. In this article, we looked at three methods of concatenating DataFrames using concat(), row-wise, column-wise and how we can combine DataFrames with missing values. Using these methods we can now efficiently visualize our DataFrames and manipulate them smoothly.
Reference
https://stackoverflow.com/questions/53877687/how-can-i-concat-multiple-dataframes-in-python





