
New to Rust? Grab our free Rust for Beginners eBook Get it free →
What is RLHF? How It Works in ChatGPT

Artificial Intelligence is coming a long way and one of the most interesting developments in the past years has been a conversational AI model that was created by Open AI named — ChatGPT. Yet have you ever wondered how ChatGPT could understand and reply to the human language so well?
Reinforcement Learning from Human Feedback (RLHF) is one of the key techniques that make it successful. So, in this post, we’ll get a basic introduction to what exactly RlHF is and then examine how it operates and holds so much value for ChatGPT.
Reinforcement Learning from Human Feedback (RLHF) Explained
RLHF stands for Reinforcement Learning from Human Feedback. The training technique helps AI models including ChatGPT develop better responses through human feedback. The process resembles child development where parents provide rewards upon correct behavior but also address errors made by their children. Through RLHF ChatGPT acquires the ability to identify responses that provide helpful accurate and appropriate answers.
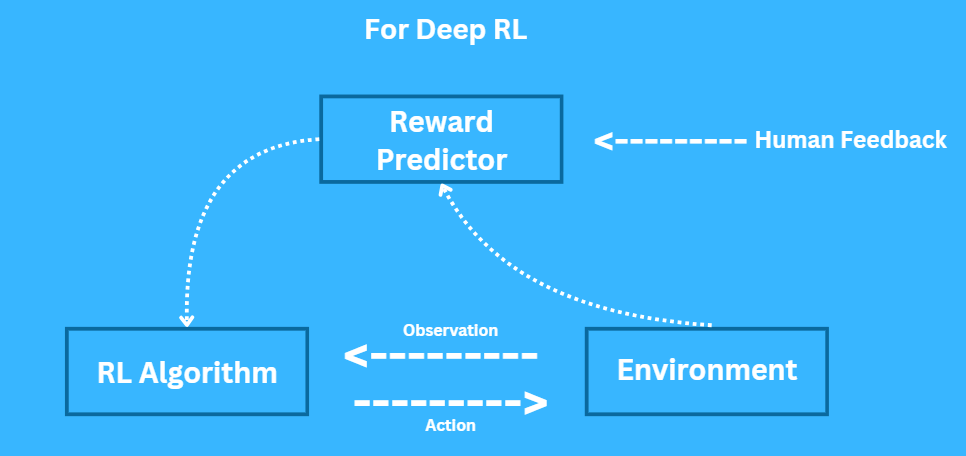
For Example: Consider teaching a dog to fetch a ball. The dog receives a treat (reward) whenever it returns with the ball during the training sessions. It will get its reward only after returning the ball successfully. It develops a pattern of fetching the ball because doing so leads to obtaining a reward.
But before we dive into RLHF, let’s take a step back and understand how ChatGPT is built.
How ChatGPT is Trained
The foundation of ChatGPT rests upon Large Language Models (LLM). The training process involves extensive text data extraction from books, websites and additional sources. A two-step training process makes up the core methodology of ChatGPT:
- Pretraining: The model develops an ability to forecast the upcoming word in a sequence. When you type “The cat is on the…” the model develops the ability to predict the following word will be “roof” or “mat.” The training process enables the model to master grammar alongside fact retention and basic logical operations.
- Fine-Tuning: The model undergoes fine-tuning following pretraining to enhance its performance on particular assignments including dialogue-based tasks. RLHF operates in this phase.
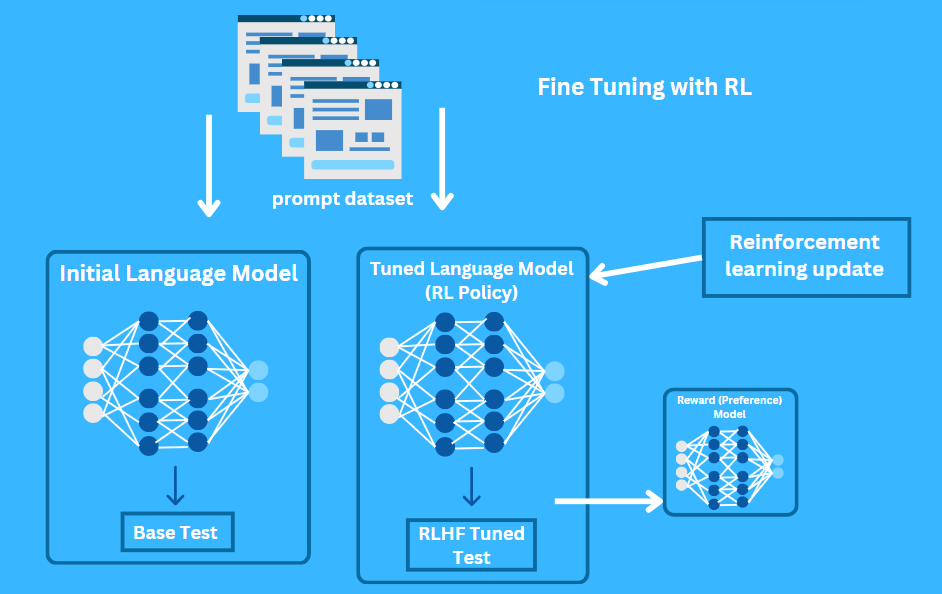
Why Is RLHF Important for AI Models?
The pretraining process does not guarantee that ChatGPT will provide optimal responses. The system might produce statements that are factually wrong or unrelated to the topic or contain inappropriate content. The model lacks built-in understanding of what constitutes a good or bad response. It only knows how to predict the next word based on patterns in the data it was trained on.
For example, if you ask ChatGPT, “What is the capital of France?” it might correctly say “Paris.” But if you ask, “Can you tell me a joke?” it might give a funny joke or a completely nonsensical one. Through RLHF training the model acquires knowledge about which responses lead to better human satisfaction.
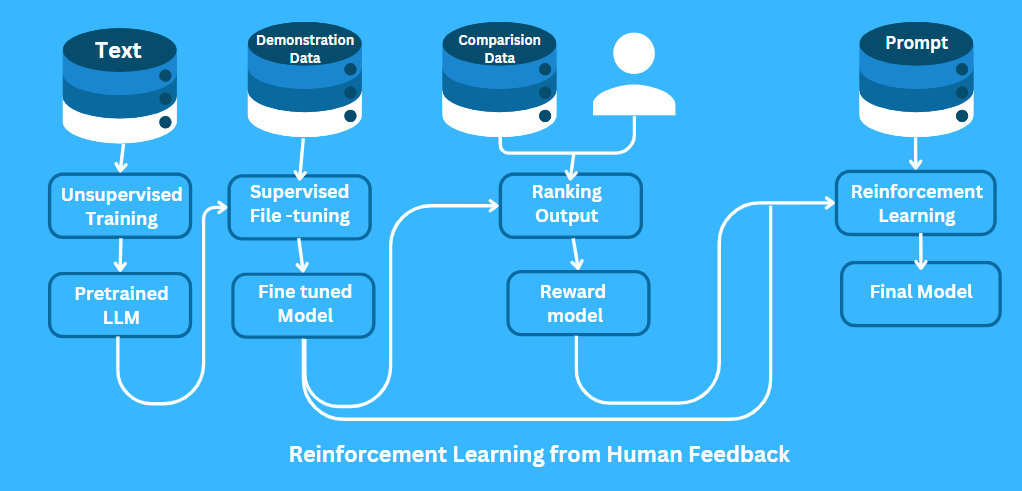
How RLHF Works – Step-by-Step Explanation
RLHF is a three-step process:
Step 1: Collecting Human Feedback
Human trainers show model examples of correct and incorrect responses. For example, if you ask, “How do I bake a cake?
A proper response should present detailed instructions whereas an improper response would contain either irrelevant or insufficient information. The model receives examples that show what makes answers helpful through this process.
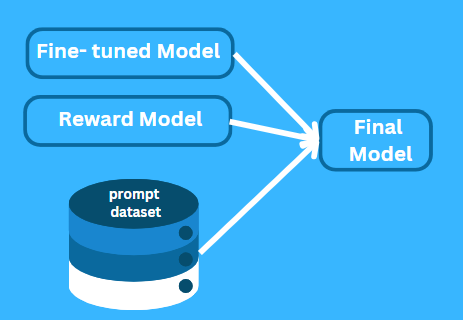
Step 2: Training a Reward Model
The human feedback serves as training material to develop the reward model. The scoring system of the model determines response quality through its evaluation process. A clear answer with accurate information will earn a high score but confusing or incorrect responses will get lower scores.
Step 3: Fine-Tuning with Reinforcement Learning
ChatGPT receives its final training through reinforcement learning. The reward model evaluates the responses that the model produces. The model receives a reward when it produces a response that scores highly which leads to its future generation of comparable outputs. The model learns to change its behavior pattern when it receives a low score from the reward model.
Example of RLHF in Action:
Let’s say you ask ChatGPT, “What’s the best way to learn a new language?” The model without RLHF training would provide a general unhelpful response like “Just practice a lot.”
RLHF enables the model to develop a comprehensive response that offers practical guidance such as:
- A learning process should begin by introducing fundamental vocabulary as well as grammar principles.
- You should use Duolingo along with other language learning applications.
- Practice speaking with native speakers.
- The target language should be your main source for movies and music listening.
This response is more beneficial because it derives from human evaluations of high-quality answers.
Why Does RLHF Matter? The Key to Better AI
- Through RLHF ChatGPT delivers superior responses that are more fitting to user queries.
- ChatGPT can hold more natural and engaging conversations.
- The model learns to prevent harmful content through human feedback input.
- RLHF establishes a mechanism which enables the model to behave according to human standards of acceptable conduct.
- The absence of RLHF could allow ChatGPT to generate dangerous medical recommendations which would otherwise be avoided through its learning process. The model develops the ability to prevent dangerous errors through RLHF while delivering secure and accurate outputs.
Challenges and Limitations of RLHF
The power of RLHF comes with imperfections. Here are some challenges:
- A human trainer’s biases can potentially transfer to the model during training. When trainers display preference for specific types of jokes the model tends to choose those jokes regardless of their overall funniness.
- The process of obtaining human feedback proves both expensive and time-consuming for scalability purposes. The method proves difficult to expand for processing all potential questions and situations.
- When the model aims to achieve maximum scores from the reward model it can lose its creative and diverse response capabilities.
Conclusion
RLHF enables ChatGPT to become smarter and safer and more user-friendly through the learning process of human feedback. ChatGPT learns to give improved responses through human feedback and prevents dangerous content while adapting to human ethical standards.
The technique of RLHF has brought major progress to the development of conversational AI despite facing ongoing obstacles. So, the next time you chat with ChatGPT and get a helpful, accurate response, you’ll know that RLHF played a big role in making that happen.
Here are more ChatGPT-related reads that you might find interesting:
- How to Use ChatGPT: All Basics Covered
- How to Write the Perfect ChatGPT Prompt: A 2024 Guide
- DeepSeek vs ChatGPT: Which Is the Best AI Chatbot in 2025?
Reference





