
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Replace Multiple Values in a DataFrame Using Pandas

Pandas is a data analysis and manipulation library in Python that allows the user to read and work with different types of data. In order to store and manipulate data, Pandas uses DataFrames. DataFrames in pandas are two-dimensional mutable tabular structures, containing rows and columns much like a spreadsheet. In this article, we will be focusing on replacing multiple values in a DataFrame with Pandas along with some examples.
Also Read: How to Check if Pandas DataFrame is Empty (3 Ways)
Methods to Replace Multiple Values in a DataFrame
There are numerous ways in which we can replace multiple values in a DataFrame. In this section, we’ll look at three distinct methods of achieving this. Before we start working with DataFrames, we must make sure that Pandas is installed in our system. If not, we can easily install it in our system through the below command.
pip install pandas
Three different methods we’ll be looking at are as follows:
- Using replace() with dictionaries
- Using loc[] for conditional replacement of values
- Using regex
Now let’s understand these methods with examples.
Using replace() with dictionaries
The simplest way to replace data in a DataFrame is using the replace() method. Let us first understand its syntax.
Syntax:
DataFrame.replace(to_replace=None, value=_NoDefault.no_default, *, inplace=False, limit=None, regex=False)
- to_replace: A required argument specifying the value that you want to replace. It must already be present in the DataFrame.
- value: The alternate value that you want the original value to be replaced with. This is also a required argument
- inplace: An optional argument that specifies if DataFrame is modified in place.
- limit: Sets the maximum number the values that can be replaced in the DataFrame.
- regex: Specifies if the value is a regular expression or not.
Now let’s use replace() in an example.
Example:
In order to replace values, we must first create a DataFrame.
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns = ['Name', 'Deparment', 'age'],
)
print(sample)
Our DataFrame is stored in sample and contains 3 columns which are assigned column names using the columns list.
Output:
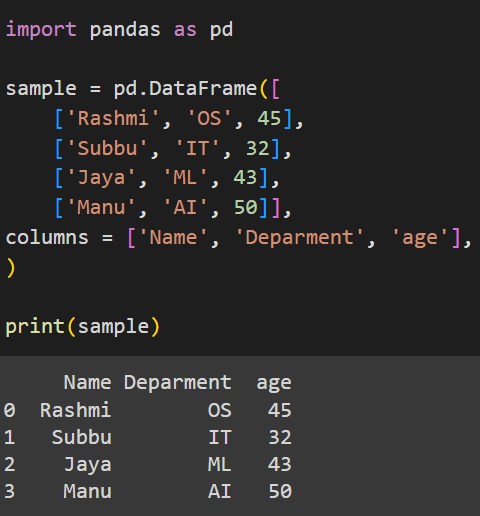
This is our original, unmodified DataFrame. Now to modify its values we will use replace().
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns = ['Name', 'Deparment', 'age'],
)
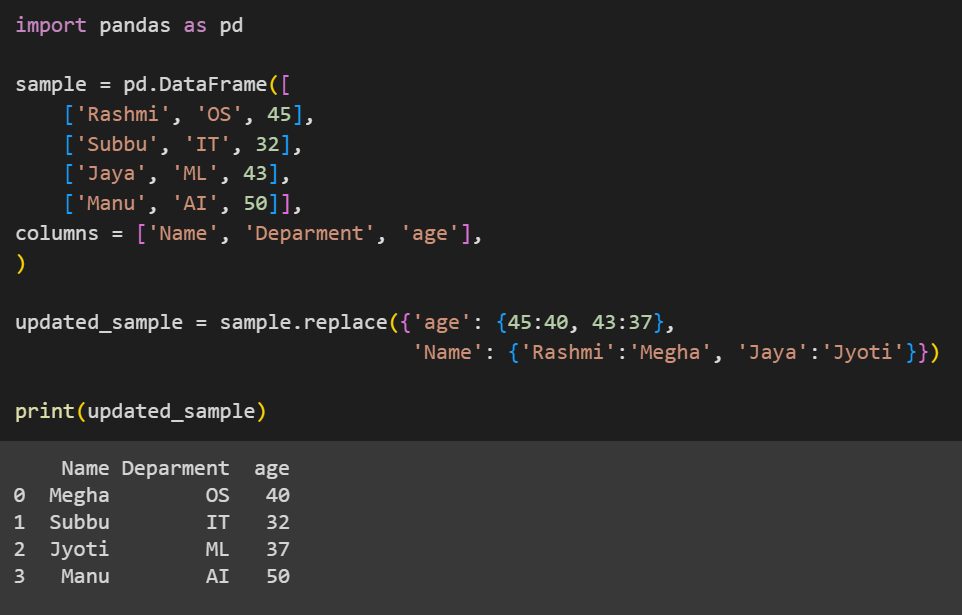
updated_sample = sample.replace({'age': {45:40, 43:37},
'Name': {'Rashmi':'Megha', 'Jaya':'Jyoti'}})
print(updated_sample)
Here, we will update values by passing in dictionaries to the replace() method. We will store the modified DataFrame in updated_sample. We get the modified DataFrame by printing updated_sample.
Output:
Using loc[] for conditional replacement of values
If we want to replace values of a DataFrame based on certain conditions then we can use the loc[] attribute. It takes in the names of rows and columns respectively as indices and returns values from the DataFrame. We can set certain constraints or conditions while passing the rows and columns into loc.
Example:
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns = ['Name', 'Deparment', 'age'],
)
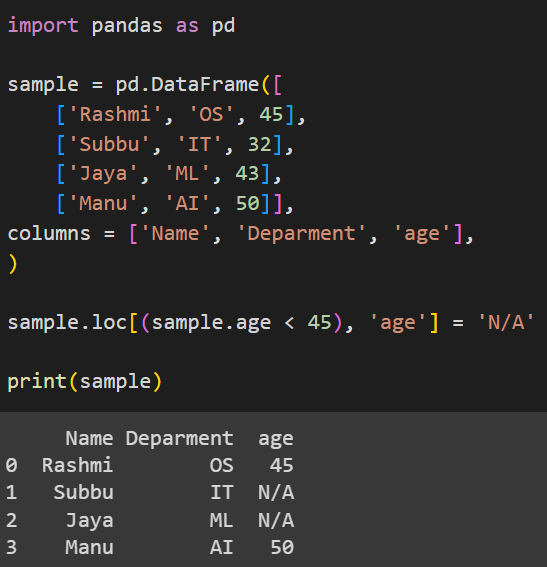
sample.loc[(sample.age < 45), 'age'] = 'N/A'
print(sample)
Here, we use the loc attribute on our DataFrame sample. We set a condition on the rows that the age must be less than 45 on the selected column, the column selected in this case is age. Once we have selected the values using loc, we assign a new value ‘N/A’ for all ages less than 45 in the age column.
Output:
Using Regex
Regex (Regular Expressions) is commonly used to define a search pattern using a specific sequence of characters. We can use a regex pattern to search for a particular data and modify it in the DataFrame.
Example:
import pandas as pd
sample = pd.DataFrame([
['Rashmi', 'OS', 45],
['Subbu', 'IT', 32],
['Jaya', 'ML', 43],
['Manu', 'AI', 50]],
columns=['Name', 'Department', 'Age']
)
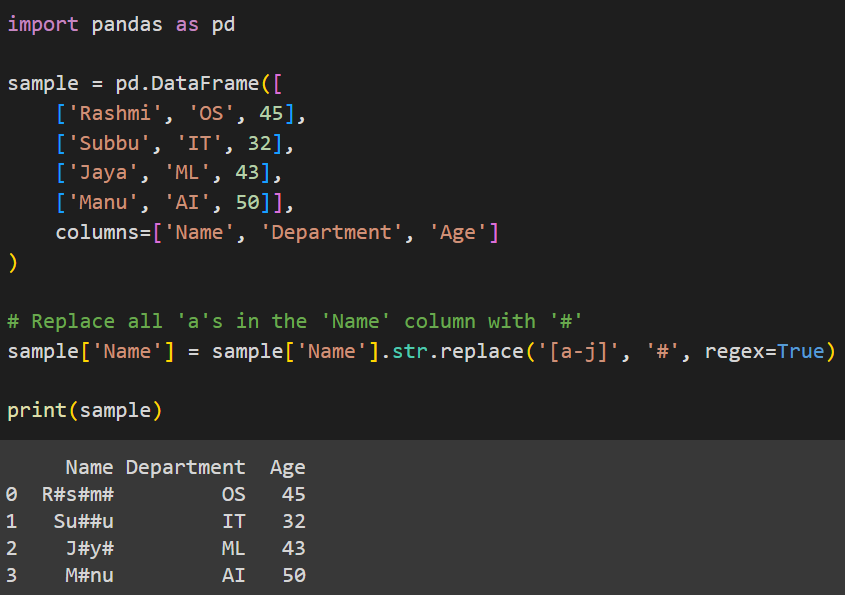
# Replace all 'a's in the 'Name' column with '#'
sample['Name'] = sample['Name'].str.replace('[a-j]', '#', regex=True)
print(sample)
Here we use the regex [a-j] to indicate all characters between a to j including a but not j (only characters till i) should be replaced. The character they are replaced with is #. The parameter regex is set to True as we are using regular expressions.
Output:
Conclusion
Modifying a DataFrame is an essential skill to know when it comes to working with DataFrames in Pandas. In this article, we’ve explored three unique ways in which we can replace certain row and column values in a DataFrame using – the replace() function with dictionaries, using the loc attribute and using regex patterns for searching substrings. Understanding these methods will make data manipulation simpler and more efficient.
Reference





