
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Mixture of Experts DeepSeek: How MoE Models Work

Artificial Intelligence (AI) is transforming the manner in which we communicate with technology, create content, and address problems. In the background, advanced AI models like DeepSeek are redefining boundaries by using new methods. One of them is MoE (Mixture of Experts), a strong approach that improves the power of AI, making it intelligent, faster, and more efficient.
Here, we’re going to break down what MoE is, how it works in DeepSeek, and why it’s so groundbreaking—all in simple, easy-to-read language. If you’re new to AI or simply curious, this is the guide for you!
Mixture of Experts Explained
Let us begin with the fundamentals. MoE is a Mixture of Experts. Suppose you are working on a group project, and each member of the group has specialized in a unique subject area. If the project is about math, history, and art, you would go to the math expert for calculations, the history buff for pertinent dates, and the artist for concepts on designs. Combined, their respective strengths yield a superior outcome.
MoE behaves in the same way in AI:
- Multiple “Experts”: The AI comprises many smaller sub-models, or experts, each carefully trained to handle specific types of tasks.
- A Smart Router: When it faces a question or problem, the AI uses a router that identifies which expert or experts are best suited to answer it.
- Combine Results: All the answers of selected experts are combined into a single correct answer.
Why MoE Models Are Useful
- Saves Time: Traditional AI models use one giant “brain” to solve every problem. This can be slow and inefficient. But MoE only activates the experts needed for a task, saving time and computing power.
- Efficiency: Instead of employing a massive network per task, the most pertinent experts are employed, which leads to a conservation of computational power.
- Scalability: MoE models can be scaled in terms of size by adding more experts without a corresponding increase in computation per input handled. Such a benefit allows for handling very large datasets.
- Specialization: Experts are trained to handle particular work or information of particular kinds, and they sharpen their skills to a large extent. Specialization tends to be followed by improved overall performance.
How MoE Works
Visual aids will come a long way in explaining to us how MoE operates, so let us examine a simplified flow chart:
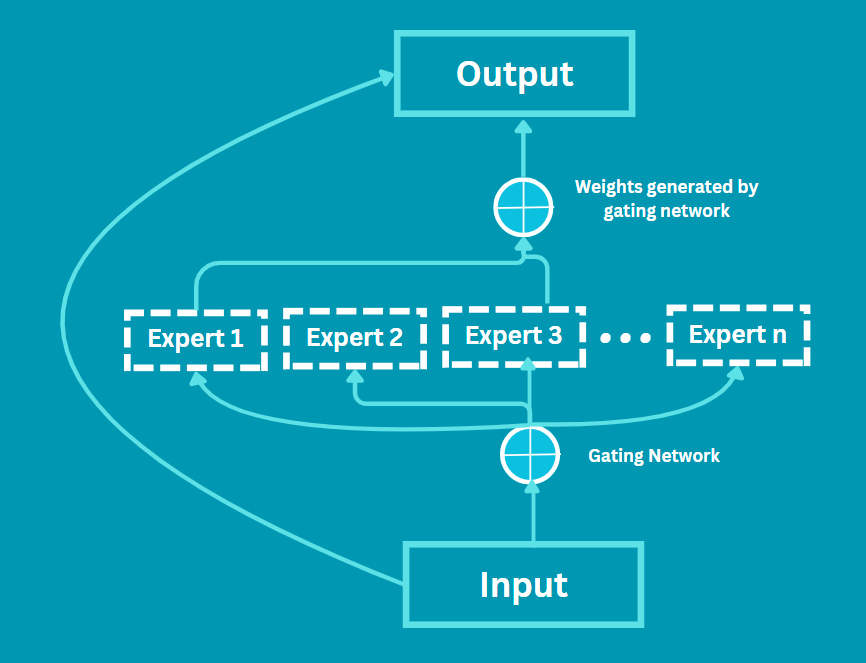
- Input Data: This is the unprocessed data that the system has to process. It could be text, a picture, or some other type of data.
- Gating Network: Once it receives the input, this network thoroughly scrutinizes the information and decides which expert(s) would be most appropriate to provide the advice. It is a decision module.
- Experts: Every experts is dealing with that part of the problem that best suits his or her expertise. The diagram shows a few examples, but in practice, there may be many experts.
- Combine Outputs: Finally, all the expertise is brought together to produce the end result. The combined effect is more accurate since it combines the strength of many focused insights.
How MoE Works in DeepSeek
DeepSeek, a top AI firm, employs MoE to construct models that are efficient as well as capable. Here’s how they achieve this:
Step 1: Training the Experts
Every expert in DeepSeek’s MoE system is trained on various kinds of data. For instance:
- Expert A may specialize in science and technology.
- Expert B can specialize in finance and economics.
- Expert C might handle language and creativity.
This ensures that every expert becomes very proficient in their field.
Step 2: The Router’s Job
The router works similarly to a traffic controller. Every time you ask DeepSeek something, the router:
- Analyses the input: What is the question about? Is it technical, creative, or factual?
- Chooses experts: It chooses 1-3 most applicable experts (involving only them, not everyone).
- Weighs their contributions: The router decides how much to “trust” each response from an expert.
Step 3: Blending Responses
The selected experts analyze the input individually. Their answers are then combined based on the router weights. For instance, if a question is 70% economics and 30% climate, the output response will be that proportion.
Basic Prompt Example
To better see how MoE works in practice, let us use a simple example of a prompt. This one is meant to illustrate the procedure in a formal, step-by-step fashion.
Example Prompt: “Explain the process of photosynthesis in simple terms.”
How the MoE System Responds to the Prompt:
1. Input Processing: DeepSeek accepts the prompt and forwards it to the gating network.
2. Gating Network Decision:
The gating network thoroughly examines the question. Knowing that the question requires both scientific backing and language generation, it decides to engage two experts:
- Expert A: Specialized knowledge in scientific concepts (biology).
- Expert B: Specialized in natural language processing, focusing on clarity and simplicity.
3. Parallel Expert Processing:
- Expert A explains the scientific process of photosynthesis in detail, carefully outlining the fundamental components like the role of chlorophyll, the role of sunlight, the role of water, and the role of carbon dioxide.
- Expert B rephrases the explanation in simpler and more understandable language to novices without employing very technical terms.
4. Aggregation of Outputs: The findings of both the experts are then synthesized. The final result describes photosynthesis in scientifically correct but easily comprehensible terms.
Advantages of MoE in DeepSeek
- Enhanced Accuracy: By using experts for different assignments, Deepseek can provide results that are nuanced as well as accurate. Each expert contributes their best expertise, making the final result richer.
- Reduced Computational Costs: By only involving the necessary experts, Deepseek does not waste time and resources on unnecessary components of the model for a specific input.
- Greater Scalability: MoE architecture allows Deepseek to scale up its operations, supporting bigger and more complex datasets without a proportional rise in computational load.
These benefits make Deepseek a force to be reckoned with, capable of performing an array of functions—ranging from simple queries to complex reasoning questions—all because of the exemplary use of MoE technology
Conclusion
In short, MoE, or Mixture of Experts, is a bright idea for structuring AI models. Using trained specialists in concert with a clever router, DeepSeek offers speedy, accurate, and effective solutions to complex dilemmas. Your questions may pertain to science, finance, or the subtle aspects of day-to-day existence, but MoE ensures the AI draws from the most appropriate “brain” for the assignment.
With the advancement of technology through artificial intelligence, methods like MoE will be a huge contributor to technology becoming smarter and more accessible. DeepSeek’s innovative approach is just the beginning—what is next for MoE to fix?
If you are interested in AI working techniques, here are some more articles for you:
- What is RLHF? How It Works in ChatGPT
- DeepSeek R1 Explained: How the Chain of Thought Model Works
- What Are Tokens in ChatGPT – A Simple Explanation





