
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Comparison of Top AI Models: ChatGPT, Claude, Gemini, Qwen, LLaMA, and DeepSeek R1

Every corner of modern technology demonstrates the widespread presence of Artificial Intelligence (AI) tools such as ChatGPT, Claude, Gemini and their counterparts yet customers need to understand their comparative differences. People new to Artificial Intelligence commonly encounter confusing terminology including “GPQA Diamond and “latency.” Don’t worry! The guide divides information into five core parameters to explain model functionalities alongside their optimal use and supporting reasons. Let’s dive in!
1. Coding Skills
The coding skill measurement determines how well the model performs on code generation and debugging, as well as explanations about code.
Comparison:
- ChatGPT (OpenAI): The model releases short code fragments (for example calculator applications) as well as technical explanations in basic language. The system faces difficulty completing highly complicated tasks.
- Claude 3 (Anthropic): It handles advanced coding better. For example, it can debug a 100-line Python script or explain how to connect a database to a website.
- Gemini (Google): It specializes in Google-friendly tools like Google Colab (a coding platform) or integrating APIs (tools that let apps talk to each other).
- Qwen2.5 (Alibaba): Best for coding in Chinese. The system displays better understanding of native language constructs and regional expressions than other programmes.
- Llama 3 (Meta): Coders use this for free hobbyist projects because of its open-source nature, but it offers limited capability for professional work environments.
- DeepSeek-R1: This targets data science operations, including spreadsheet analysis and graphical creation.
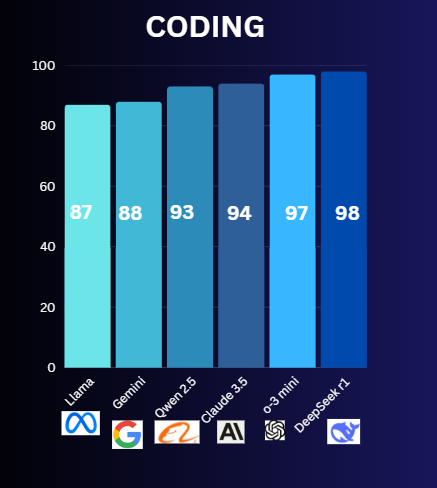
Winner: Deepseek R1
Why: R1 provides a balance between easy features for starters together with the capabilities to manage complex development tasks.
2. Mathematical & Quantitative Reasoning (Math-500)
This tests how well an AI solves math problems—from basic arithmetic to calculus or logic puzzles. The “Math-500” benchmark is like a final exam with 500 tricky questions. Higher scores indicate better performance on problems ranging from algebra to calculus.
Comparison:
- ChatGPT (OpenAI): It is good for simple math (e.g., splitting a restaurant bill) but often fails at advanced problems.
- Claude 3 (Anthropic): Scores ~75% on Math-500. The model provides explanations through detailed steps similar to what a teaching assistant would do.
- Gemini (Google): It is reliable for step-by-step algebra or geometry help but slower.
- Qwen2.5 (Alibaba): It receives training through Asian math Olympiad problems to tackle competitive questions at its best.
- Llama 3 (Meta): It follows basic math only (e.g., percentages, fractions).
- DeepSeek-R1: Built for math! Engineers and financial professionals can benefit from this since its Math-500 performance reaches 97% accuracy.
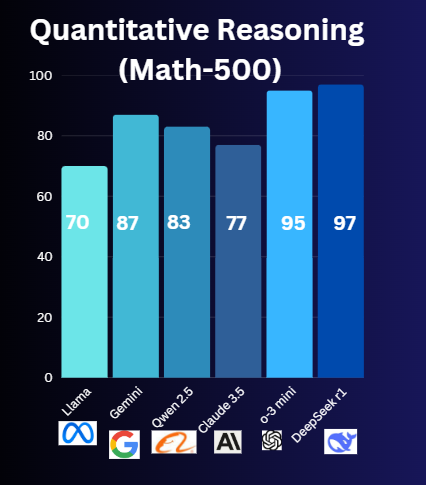
Winner: Deepseek R1
Why: DeepSeek-R1 functions as an AI version of a math genius.
3. Scientific Knowledge & General Problem-Solving (GPQA Diamond)
The GPQA Diamond presents PhD-level questions from biology physics and chemistry through a challenging test format. To verify its accurate and detailed responses, the benchmark measures how well an AI understands explanations on topics like quantum mechanics and vaccine functions.
Comparison:
- ChatGPT (OpenAI): It displays excellence in bioinformatics which involves using computers to analyze genes in data-intensive domains.
- Claude 3 (Anthropic): The model delivers intricate details in easy-to-understand explanations similar to textbook explanations.
- Gemini (Google): It uses Google Scholar (a research database) to stay updated on new discoveries which is great for cutting-edge topics like climate change tech.
- Qwen2.5 (Alibaba): It is strong in chemistry and materials science
- Llama 3 (Meta): It should be avoided for scientific matters because it fails to offer detailed explanations.
- DeepSeek-R1: Broad knowledge but shallow. The system can explain basic DNA concepts but struggles with more complex genetic topics.
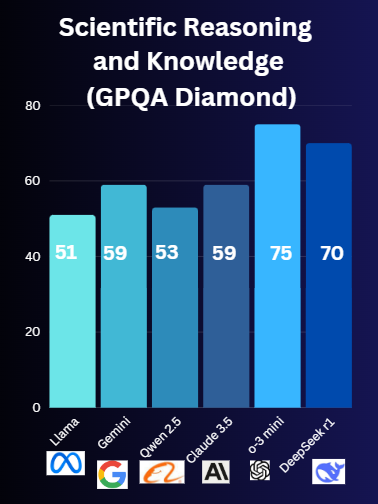
Winner: ChatGPT o1
Why: o balances depth and simplicity, making even tough topics easy to grasp.
4. Artificial Intelligence Analysis Quality Index
The scale from 0 to 100 determines the degree to which an AI evaluation appears “human” and dependable. The model’s ability to process information while generating clear reasoned conclusions determines its AAQI score which evaluates overall human-like performance. A higher AAQI indicates that the AI responses deliver precise and insightful outcomes which are also easy to comprehend.
Comparison:
- ChatGPT (OpenAI): The model achieves an 84/100 score for creativity yet generates false information (hallucination) sometimes. Brainstorming benefits from it however serious tasks may become compromised because of its use.
- Claude 3 (Anthropic): Less reliable. Businesses use it for reports or contract reviews.
- Gemini (Google): (82/100) It is great for visual data (e.g., turning spreadsheet numbers into charts).
- Qwen2.5 (Alibaba): (75/100) specifically targets Asian market trends to predict e-commerce demand levels.
- Llama 3 (Meta): (70/100): It can be used for basic summaries only.
- DeepSeek-R1: (89/100) It is rated at the highest and can predict sharp for financial stats (e.g., company revenue forecasts).
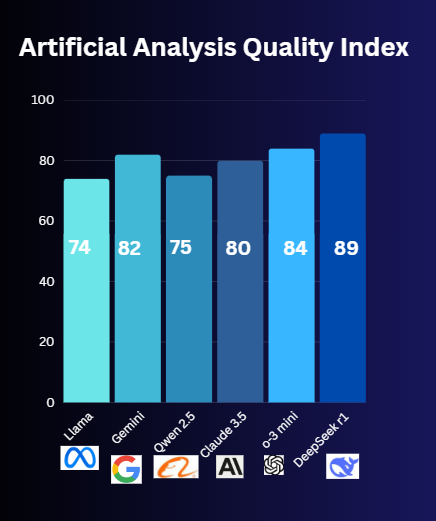
Winner: Deepseek R1
Why: This system provides trustworthy analysis suitable for academic use and professional tasks throughout your research.
5. Model Latency & Response Time
Latency is how fast an AI responds after you ask a question. When latency stays low you will receive faster responses to your questions. Low latency remains essential in delivering optimal performance for real-time applications.
Comparison:
- ChatGPT (OpenAI): The latency of o1 falls between 31 to 32 seconds.
- Claude 3 (Anthropic): About 1 sec.
- Gemini (Google): It is fast with 0.73 sec latency
- Qwen2.5 (Alibaba): It has decent latency of 1.73 sec.
- Llama 3 (Meta): Very quick, ) 0.72 sec.
- DeepSeek-R1: It has the highest latency of 71.22 because of busy servers due to many users and open source.
Winner: Llama and Gemini
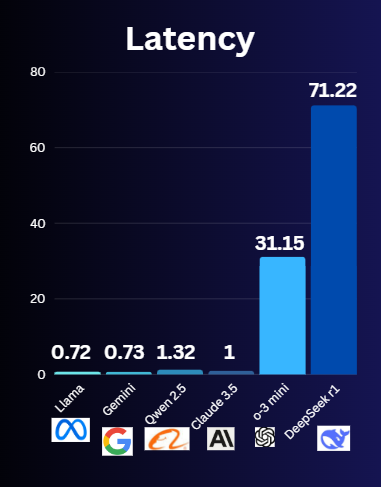
Why: Speed matters for quick questions like “What’s the capital of France?” LOL!
When Should You Use Each AI Model?
Here’s a cheat sheet for beginners:
- Coding Projects
- Simple: ChatGPT
- Complex: Claude 3
- Chinese Support: Qwen2.5
- Math & Finance Homework
- Basic: ChatGPT
- Advanced: DeepSeek-R1
- Science & Research
- General: Claude 3
- Latest Discoveries: Gemini
- Business & Data Analysis
- Most Reliable: Claude 3
- Financial Stats: DeepSeek-R1
- Quick Everyday Questions
- Fastest Response: Gemini
No AI is perfect, but this guide helps you match the tool to your task!
Conclusion
The AI world is changing fast, and every model—ChatGPT, Claude, Gemini, Qwen 2.5, LLaMA, and DeepSeek R1—is good in its own field. If we look at them from the perspective of coding, mathematical skills, scientific thinking, overall quality, and speed, we can conclude that the best one for you is what you need to accomplish. With these models changing, knowing their strengths will enable you to select the best tool for your project.
If you find reading about AI interesting, check out the following articles:
- DeepSeek R1 Explained: How the Chain of Thought Model Works
- What Are Tokens in ChatGPT – A Simple Explanation
- What is RLHF? How It Works in ChatGPT
- DeepSeek vs ChatGPT: Which Is the Best AI Chatbot in 2025?





