
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Node.js Cluster Module: Improve Node.js Code Performance

Node.js programs, by default run in single thread mode. This means that by default your Node.js code is running on a single core of your processor.
I believe every computing machine nowadays comes up with multi-core processor and you should take advantage of them.
So is your Node.js application taking advantages of those cores and utilizing the resources?
Well if you are not running it on the cluster, then probably you are wasting your hardware capabilities.
In this tutorial, I am going to explain one of the awesome features of Node.js which allows you to utilize all the cores of your machine. It’s called “Cluster Module”.
What is clustering ?
Clustering in Node.js allows you to create separate processes which can share same server port. For example, if we run one HTTP server on Port 3000, it is one Server running on a Single thread on a single core of the processor.
But I want to take advantage of all core available on my machine. So I will cluster my application and run them on all cores. So if I run one server on Port 3000 by having 4 core processor then actually I am running 4 servers all are listening to Port 3000.
So if one server goes down the other is there to take the place of it, also in peak load of traffic, Node will automatically allocate the worker to particular process so basically it does internal load balancing very efficiently.
Code which does this Magic.
The code shown below allows you to cluster your application. This code is official code represented by Node.js.
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
// Fork workers.
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
Object.keys(cluster.workers).forEach(function(id) {
console.log("I am running with ID : "+cluster.workers[id].process.pid);
});
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
} else {
//Do further processing.
}
If you observe the code, we are loading Cluster module in the first line. Then we are counting how many cores do we have on our machine. Then in "if" condition, we are checking that if its Master process then creates the copy of the same process by the number of core times.
If it is not the Master machine then basically run our normal Node program. So there would be one process which is master which in turn create processes number of core time.
In my case, i have Intel i5 consist of 4 core processor. If i run this code, i will get this output in terminal.
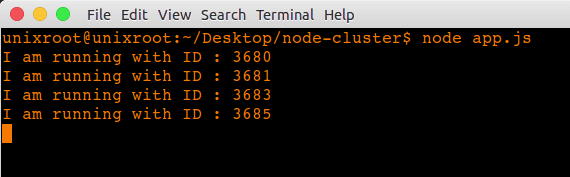
Our project:
I have covered Express so far as default HTTP server. So for demo purpose i am going to build simple Express program using clustering.
Directory structure:
------node_modules
|---express
--- app.js
--- cluster.js
--- package.json
So here is package.json.
package.json
{
"name": "cluster-demo",
"version": "0.0.1",
"dependencies": {
"express": "^4.10.6"
}
}
Install Express by running.
npm install
Here is our express code.
app.js
var express=require("express");
var app=express();
app.get('/',function(req,res){
res.end("Hello world !");
});
app.listen(3000,function(){
console.log("Running at PORT 3000");
});
Here is main file. In order to use this file in your production server, just change the last line.
cluster.js
var cluster = require('cluster');
var numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', function(worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
} else {
//change this line to Your Node.js app entry point.
require("./app.js");
}
So now to run your server type,node cluster.js You should see this output with above code.
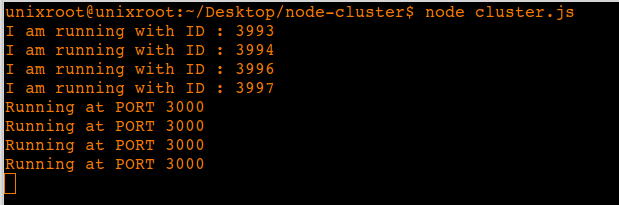
Performance analysis:
If we tweak above code little bit and add line to show Process ID which serve the request, we will get following response if we try to access localhost:3000 in different browser or client.
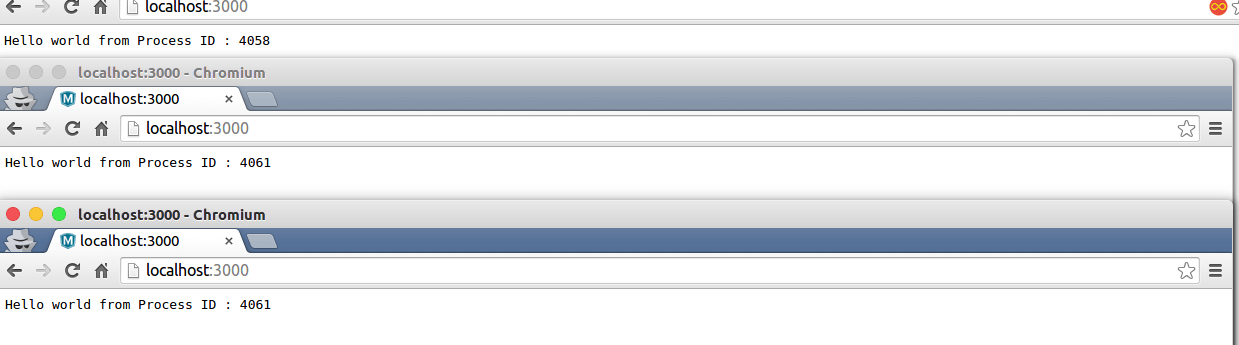
Notice anything in process IDs, Since i am running this code on Localhost most i can find to prove clustering is this only, although if we run this code on production workload we may get different response.
For example, suppose you are getting 1000 request in a minute to Port 8000. Before clustering, all request will be served by this instance of the program.
After clustering, you have 4 copy of your program running and listening on Port 3000. So just for example, in one minute 1000 request will be divided to 250 for each core. So together performance will increase.
This is just, for example, internal load balancing is done by the node itself.
Conclusion:
In the local environment, you may not be able to judge exact performance improvement but I believe in production workload this technique will help you a lot to improve the throughput of your System and utilize resources at the top.
Also, a quick tip, if you are running your code in production then I highly recommend PM2 with keymetrics. PM2 supports clustering in a simple command line. Check out the complete article here.
This is all about clustering in node.js. Share your views in comments.





