
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Migrating WordPress Content to MongoDB
WordPress uses MySQL as a primary database to store its content that includes posts, categories, tags, users, media and other meta details. WordPress also has a pretty awesome import/export feature that generates a generic XML file containing the content information.
This article is a part of Codeforgeek redesign series.
When we chose to decouple WordPress and serve the content using our custom Node.js server, we had to make an important design decision:
- Use the WordPress API to fetch content information whenever requested by the user.
- Migrate the WordPress content in the local database.
We selected the second option. According to our plan and goal, using the WordPress JSON API for each visitor cannot scale.
The plan

We wanted a simple approach using which we can perform the migration in an effective way. When we did a little research, there were no simple plug and play solution especially for NoSQL databases like MongoDB.
One of the popular approaches is to export the WordPress content and feed it to the custom program which in turn reads, parse and injects the parsed data into MongoDB.
That seems like too much work. So we tried a new approach.
WordPress provides the content information in form of API also called WPJSON API. This is perfect for the use case like us. All we had to do is call WordPress API, prepare the data for MongoDB and inject it. Simple and effective.
WordPress API
WordPress API is awesome. You can view the information related to posts, users, categories, tags, media etc in the JSON payload. Have a look for yourself.
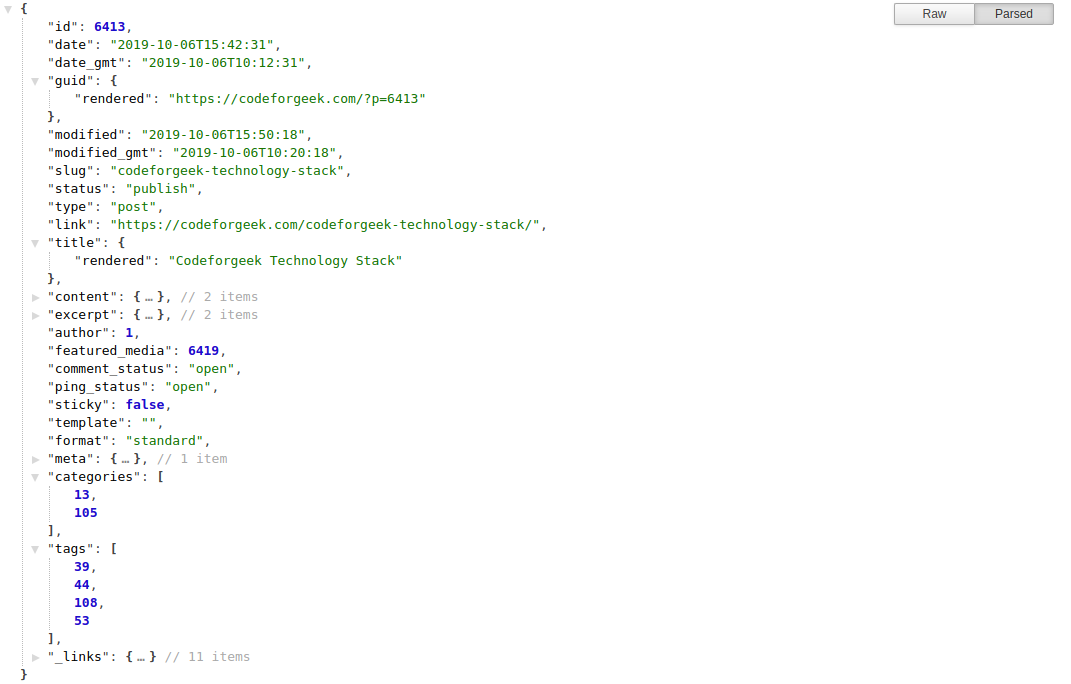
You can use the ID of each object to get fetch specific details. It’s simple and really useful.

Checkout official WordPress API documentation.
Migrating content
To migrate content we wrote a simple program in Node.js which calls WordPress API, formats the content and pushes it in the MongoDB collection. We have as of now 5 collections in our MongoDB database. They are:
* categories
* courses
* lessons
* posts
* tags
* users
We first migrated users, tags, and categories then posts and courses.
Let me show you our code that pushes the posts in MongoDB collection.
const mongo = require('mongodb');
const chalk = require('chalk');
const url = "mongodb://localhost:27017/codeforgeek";
const async = require('async');
const request = require('request');
// start the work
mongo.connect(url, {useNewUrlParser: true}, (err, db) => {
if(err) {
console.log(err);
process.exit(0);
}
var dbo = db.db('codeforgeek');
var collection = dbo.collection('posts');
// grab posts
request('https://codeforgeek.com/wp-json/wp/v2/posts?per_page=100&page=1',(err, response, body) => {
let data = JSON.parse(body);
//console.log(data);
let userData = [];
data.forEach(singleData => {
async.waterfall([
(callback) => {
// get the featured image
request(`https://yourdomain.com/wp-json/wp/v2/media/${singleData.featured_media}`,(err, res, body) => {
if(err) {
console.log(err);
return callback(null, null);
}
let data = JSON.parse(body);
console.log('featued image = ', data.source_url);
return callback(null, data.source_url);
});
},
(featueredImage, callback) => {
// get categories name
dbo.collection('categories').find({id: { $in: singleData.categories}}).toArray((err, result) => {
let catname = [];
result.forEach((singleResult) => {
catname.push({
name: singleResult.name,
slug: singleResult.slug,
});
});
console.log('categories = ', catname);
return callback(null, featueredImage, catname);
});
},
(featueredImage, catNames, callback) => {
// get tags name
dbo.collection('tags').find({id: { $in: singleData.tags}}).toArray((err, result) => {
let tagname = [];
result.forEach((singleResult) => {
tagname.push({
name: singleResult.name,
slug: singleResult.slug,
});
});
console.log('tags = ', tagname);
return callback(null, featueredImage, catNames, tagname);
});
}
], (err, image, cats, tags) => {
let parseContent = JSON.parse(JSON.stringify(singleData.content));
let formatContent = parseContent.rendered.split("\n").join('');
let formatContentspaces = formatContent.split("\t").join('');
let postData = {
id: singleData.id,
title: singleData.title.rendered,
date: singleData.date,
url: singleData.link,
slug: singleData.slug,
status: singleData.status,
type: singleData.type,
excerpt: singleData.excerpt.rendered,
content: formatContentspaces,
author: singleData.author,
categories: cats,
tags: tags,
featured_image: image
};
collection.insert(postData, (err, result) => {
if(err) {
console.log(err);
process.exit(0);
}
console.log(result);
});
});
});
});
});
As you can see in the code, we first called WordPress API to give us 100 records and we looped over those 100 records to fetch tag ID, category ID and featured image link. Once everything is fetched, we prepared the JSON for MongoDB and add it to the collection.
Once the script runs, I changed the page number in the URL to 2 and run the script again until all the posts are added to the database. We can automate that as well.
A similar approach is been taken for tags, categories, and users. You might be wondering where are the media details? It’s not in the database, we stored images in the Amazon S3 bucket and serve it using Cloudfront CDN so there was no need to store that information.
Summary
I hope you find our approach interesting and easy to use. It’s way better than parsing XML from file for sure. If this interests you and you would like to create an open-source project for that, give some likes to the article and I will surely take that into consideration.





