
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Using Pandas get_dummies() Function in Python

The field of data analytics has gone leaps and bounds within a short period of time. Technological advancements in the domain of computation have introduced new techniques to boost the efficiency at which data analysis is carried out. This article shall elaborate on a particular function from the pandas library of Python that makes life easier for data analysts – the get_dummies( ) function.
Let us start things off by importing the pandas library using the following code:
import pandas as pd
The get_dummies( ) function is further detailed through each of the following sections:
- Usage of Dummy Variables
- Syntax of Pandas get_dummies() Method
- Using Pandas get_dummies() Method in Python
Usage of Dummy Variables
Machine learning applications have a heavy reliance on numerical data. Numbers offer much needed flexibility in data analysis which is not exhibited by the case-sensitive alphabets. To make things worse, if the tildes & other punctuations are factored in, we have a complete recipe for a great mess! That’s exactly where the dummy variables arrive for the rescue.
When it comes to regression analysis through a machine learning algorithm the inputs shall strictly be numbers. Introduce a tad bit of textual data and get ready for things to go haywire, when the program is executed!
Syntax of Pandas get_dummies() Method
Dummy variables aid in the aching task of data cleaning by transforming the data in a dataframe to a numerical value. Given below is the syntax of the get_dummies( ) function.
Syntax:
pandas.get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
where,
- data – Categorical dataframe for conversion into dummy variables
- prefix – An optional component set to ‘None’ by default; used for assigning column names to the dummy variable dataframe
- prefix_sep – An optional component set to ‘_’ by default; used to differentiate the categorical entry from the column name in the dummy variable dataframe
- dummy_na – An optional component set to ‘False’ by default; used for inserting a column to indicate the positions of zeros in each column of the dummy variable dataframe
- columns – An optional component set to ‘None’ by default; used to encode the column names in the input categorical dataframe before conversion into dummy variables
- sparse – An optional component set to ‘False’ by default; if set to ‘True’, the dummy encoded columns are to be backed by a sparse array rather than a numpy array
- drop_first – An optional component set to ‘False’ by default; if set to ‘True’, the first level from the input categorical data will be removed while converting to dummy variables
- dtype – An optional component set to ‘None’ by default; used to specify the data type for the new columns of dummy variables
Using Pandas get_dummies() Method in Python
Now that we have gone through the syntax & usage of the get_dummies( ) function, it is time for us to witness a first-hand demonstration of its working with a dataframe.
import numpy as np
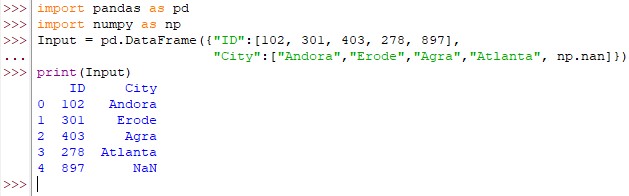
Input = pd.DataFrame({"ID":[102, 301, 403, 278, 897],
"City":["Andora","Erode","Agra","Atlanta", np.nan]})
print(Input)
Now only the City column from the above dataframe is to be selected for conversion into dummy variables.
City = Input.City
print(City)

Once done, it is time for the conversion into the dummy variables using the below code.
pd.get_dummies(City)
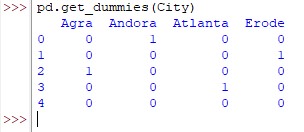
The above result is with the default setting of the get_dummies( ) function. Now, we shall tweak it a bit by using some of the components given earlier in the syntax of this function to do the following,
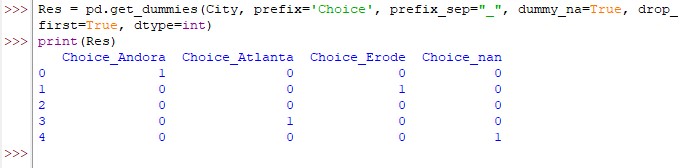
- Assign a prefix ‘Choice’ with ‘_‘ as a separator
- Include a new column to specify the positions where values are not available
- Remove the first level of categorical data (i.e) all entries under ‘Agra’ column
- Converted dummy variables to be in ‘int’ data type
When the requirements in this list are transformed into Python coding, the following shall be the result:
Res = pd.get_dummies(City, prefix='Choice', prefix_sep="_", dummy_na=True, drop_first=True, dtype=int)
print(Res)
Conclusion
Now that we have reached the end of this article, hope it has elaborated on how to use the get_dummies( ) function from the pandas library. Here’s another article that details the different datatypes in Python. There are numerous other enjoyable and equally informative articles in CodeForGeek that might be of great help to those who are looking to level up in Python.
Reference
https://pandas.pydata.org/docs/reference/api/pandas.get_dummies.html





