
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Calculating the Mean of Pandas DataFrame in Python

We know that the definition of mean is the sum of all values divided by the number of values. Similarly, the mean() method in Pandas is also used to calculate the mean or the average of the values in a DataFrame. It can be applied to the entire DataFrame or along a specific axis (rows or columns). This method is particularly useful for numerical data analysis.
Pandas DataFrame mean() Method
We have to keep in mind that the mean() method returns a series containing the mean values for each column or row, depending on the specified axis.
Syntax:
DataFrame.mean(axis=None, skipna=None, level=None, numeric_only=None)
Parameters:
- axis: {0 or ‘index’, 1 or ‘columns’}, default None. Axis along which the means are computed. If None, compute over all elements.
- skipna: bool, default None. Exclude NA/null values when computing the result. If the entire row or column is NA, the result will be NA.
- level: int or level name or list of ints or level names, default None. If the axis is a MultiIndex, compute the mean along a particular level or level.
- numeric_only: bool, default None. Include only float, int, and boolean data in the calculation. If None, will attempt to use everything, then use only numeric data. Not implemented for Series.
Calculating the DataFrame Mean
Let’s create a DataFrame using the DataFrame() method of the pandas library to demonstrate the calculation of the DataFrame mean.
Sample DataFrame:
import pandas as pd
import numpy as np
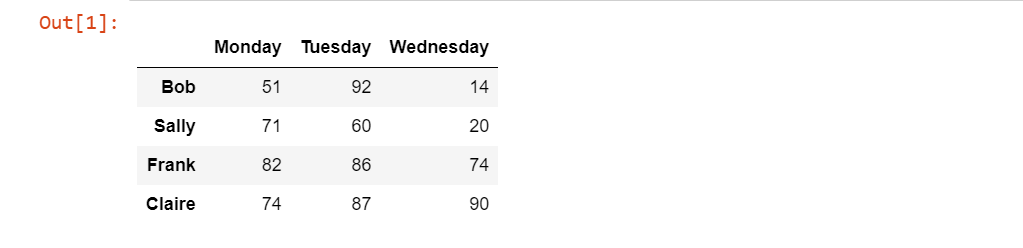
df= pd.DataFrame([[51,92,14],[71,60,20],[82,86,74],[74,87,90]],
index=('Bob', 'Sally', 'Frank', 'Claire'),
columns=('Monday','Tuesday','Wednesday')
)
df
Output:
Also Read – Create a Pandas DataFrame from Lists
Mean Across Columns
We can calculate the mean across columns just by passing the axis parameter as an index into the mean() function.
df.mean(axis='index')
Through the above code, we calculated the mean across the columns of DataFrame df means the average of Monday, Tuesday and Wednesday.
Output:

Mean Across Rows
Now if we wanted to take the average across the rows, meaning what is Bob’s average, Sally’s average and so on. For this, we can do the same thing we did above but instead of passing axis=’index’ we need to pass axis=’columns’.
df.mean(axis='columns')
Output:

Mean Across One Column
We can also calculate the mean of a single column in the DataFrame by just applying the Pandas mean function only on that particular column.
print(df['Monday'].mean())
We applied the Pandas mean function only to the Monday column of the DataFrame so that we could get an average of only the Monday column.
Output:

Handling Missing Values When Calculating the Mean
When we have NaNs or not available values in the DataFrame then how do we calculate the mean? So for demonstrate this, we will create another DataFrame and place one np.nan value in it which is just a not available number.
import numpy as np
df = pd.DataFrame([('Foreign Cinema', 'Restaurant', 289.0),
('Liho Liho', 'Restaurant', 224.0),
('500 Club', 'bar', 80.5),
('The Square', 'bar', np.nan)],
columns=('name', 'type', 'AvgBill')
)
df
Output:

Now if we run the df.mean() which means the average of the above DataFrame df then by default Pandas is going to skip over the NaNs.
df.mean()
Output:

Pandas skipped the NaN value at the 4th column and calculated the average of starting three columns only which is 197.83
However, there is a parameter skipna which is by default True but now we will set it to False so that Pandas can’t skip the NaN value.
df.mean(skipna=False)
Output:

Since there was a NaN value in the fourth row that’s why Pandas can’t take the average of that so it returns us NaN in the output.
Conclusion
Now that we have reached the end of this article, we hope it has elaborated on the different ways to find the mean of the Pandas DataFrame using the mean() function exclusively from the Pandas library. Mean, also known as the arithmetic average, is the sum of all values divided by the number of values and can be very useful when it comes to finding the average value of a dataset. CodeForGeek has many other entertaining and equally informative articles that can be of great help to those who want to advance in Python, so be sure to check them out as well.
Reference
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.mean.html





