
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Scraping the Web With Node.js

Scraping the web is a quite old technique to generate data for search engines, data science, surveillance etc. In this article, we are going to learn how to perform web scraping using Node js and a tool called proxycrawl.
What we are going to build
We are going to build a script which will crawl the Amazon website and extract useful information.
We will use the following technologies:
- Node js
- Cheerio
- Proxy crawl
About Proxy crawl
Proxycrawl is a crawling service built for developers to easily crawl the data from the web. Proxycrawl supports tons of website such as Amazon, Facebook, LinkedIn, Github etc which you can crawl. Sign up for a free account and give it a shot.
We are going to use this tool to crawl the Amazon website.
This post is sponsored by proxycrawl team.
Let’s jump into the code.
Building the Crawler
Create a new folder and initialize the Node project using the following command.
npm init --y
Then install the following dependencies.
npm i --S cheerio proxycrawl
Create a new file and store Amazon products link in it or you can download them from here.
You need a proxycrawl token in order to use the crawler. Go to the proxycrawl account section and copy the Normal request token.
Here is the script which contains the crawler code.
crawl.js
const fs = require('fs');
const { ProxyCrawlAPI } = require('proxycrawl');
const cheerio = require('cheerio');
const productFile = fs.readFileSync('amazon-products-list.txt');
const urls = productFile.toString().split('\n');
const api = new ProxyCrawlAPI({ token: '<< put your token here >>' });
const outputFile = 'reviews.txt';
function parseHtml(html) {
// Load the html in cheerio
const $ = cheerio.load(html);
// Load the reviews
const reviews = $('.review');
reviews.each((i, review) => {
// Find the text children
const textReview = $(review).find('.review-text').text();
console.log(textReview);
fs.appendFile(outputFile, textReview, (err) => {
if(err) {
console.log('Error writing file...')
}
console.log('review is saved to file')
})
})
}
const requestsThreshold = 10;
var currentIndex = 0;
setInterval(() => {
for (let index = 0; index < requestsThreshold; index++) {
api.get(urls[currentIndex]).then(response => {
// Process if response is success else skip
if (response.statusCode === 200 && response.originalStatus === 200) {
parseHtml(response.body);
} else {
console.log('Failed: ', response.statusCode, response.originalStatus);
}
});
currentIndex++;
}
}, 1000);
You should see screen similar to this.
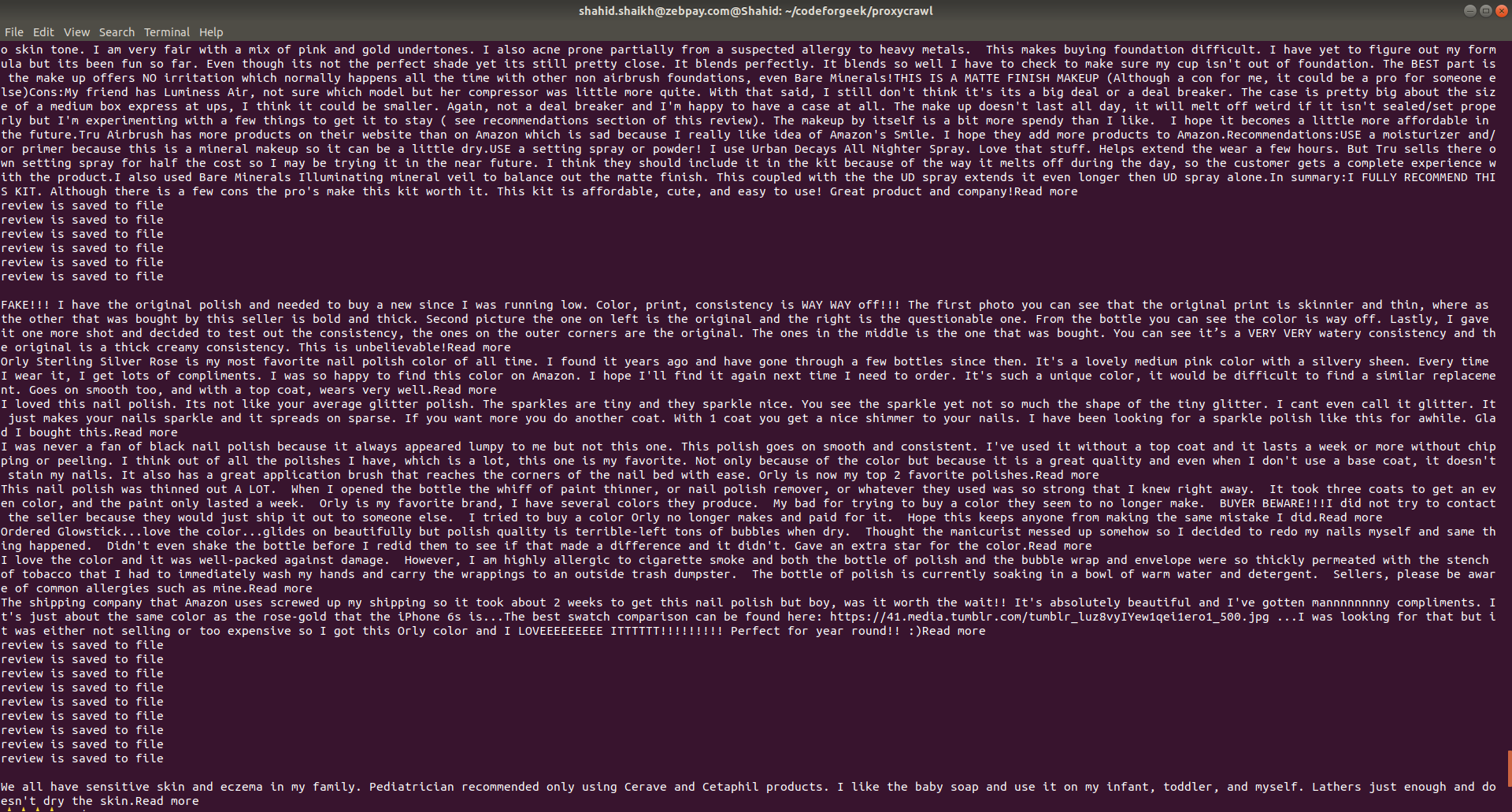
Once the script will crawl all data, you can get the reviews of each product crawled and stored in a file named reviews.txt. Open it up and see the reviews.
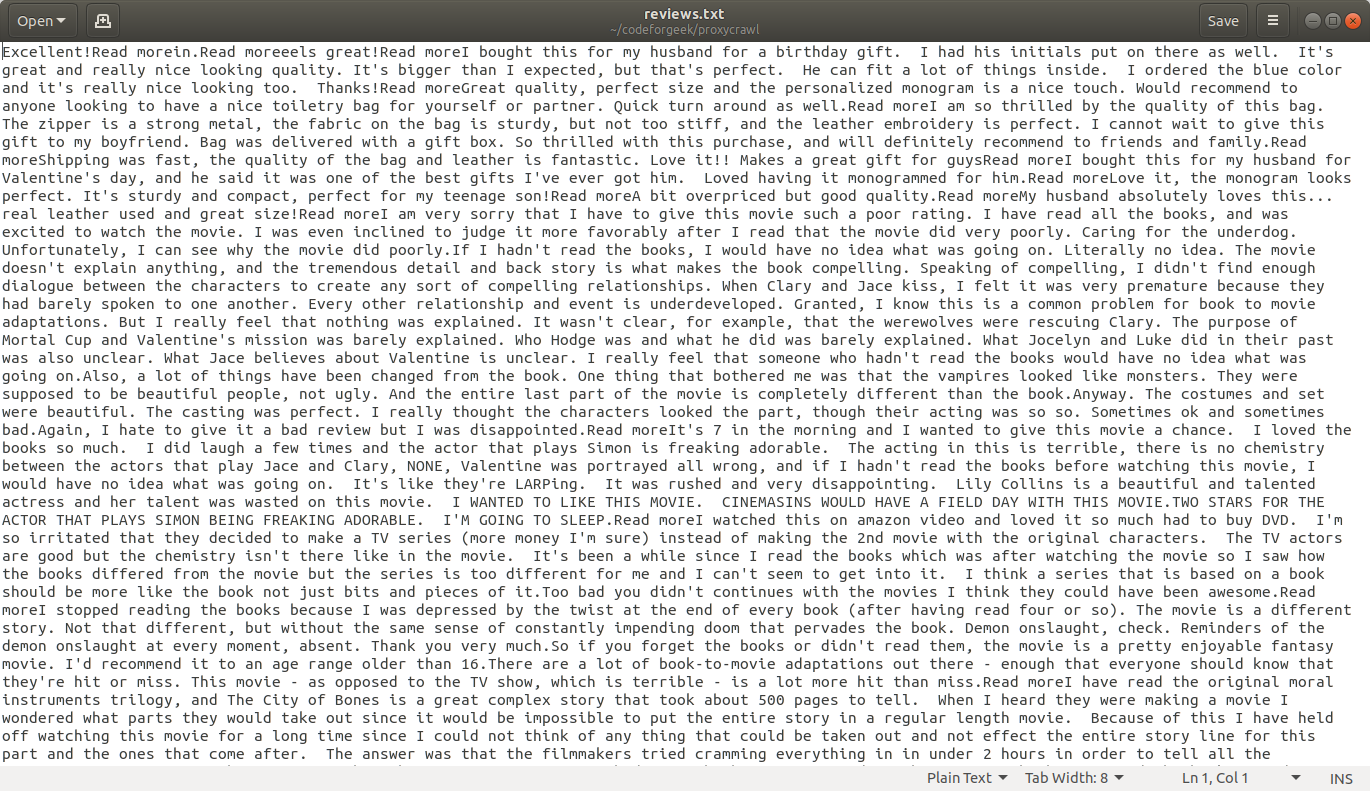
We have stored the reviews in the file, but the good use case is to store it in the database for further processing. You can consider MySQL, MongoDB or Elasticsearch as database options.
Conclusion
You can use web scraping for various purpose and proxycrawl provides a good solution to crawl the websites and later do the processing on each crawled document. You can use this tool to crawl sites like LinkedIn and push the data from LinkedIn to a custom search engine for specific job search website. It’s just an example of what you can do with it.
Let me know your experience with crawling and web scraping and how did you use it in your products.
Further Study





