
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Sharding in MongoDB: Explained in Detail

In this tutorial, we will learn about sharding in MongoDB.
It is time we learn an intermediate-level topic. Sharding in MongoDB is one such topic. Now, sharding in layman’s terms means that mechanism that stores data on multiple machines. This is done to feed the growing demand of the growth of data.
Let us dive deeper into our guide on sharding in MongoDB. This guide aims to provide a clearer and comprehensive explanation of what sharding is.
So, let us get started.
Also read: Error Testing Smart Contract in Solidity Ethereum
What is Sharding?
Sharding means storing records of data on multiple machines. This is MongoDB’s way of providing scalability to data. In other words, it makes it easier to handle massive data records.
Let me try to make it even simpler for you by giving an example. Let’s say for instance you have a laptop that can easily store 250 GB of files. You start storing a whole bunch of files over time and notice the performance of your laptop starts hampering.
The same way commercial databases store your application’s data. They store them on machines. To maintain the performance of those machines and also allow faster responses from them to your app, sharding is required.
Your application will grow over time and hence the machine does not provide read and write throughputs. It, therefore, solves the problem of horizontal scaling.
Throughputs are nothing but the amounts of data or the units of information that enter or go through a system. It is also the amount of data a system can process in a given period of time.
Why Sharding?
So, the most common question newbies ask – why sharding, why is it so important, why can’t we just stick to the traditional old way? Well, these pointers should answer your questions.
- All writes in replication are routed to the master node
- Latency sensitive queries are still routed to master
- A single replica set can only have 12 nodes
- When the active dataset is large, memory cannot be large enough
- The local disk is insufficiently large
- Vertical scaling is too costly
Understanding Sharding in MongoDB
Let us now learn sharding in MongoDB in some more detail. Here are a few representations to help us understand Sharding better sourced from MongoDB official documentation.
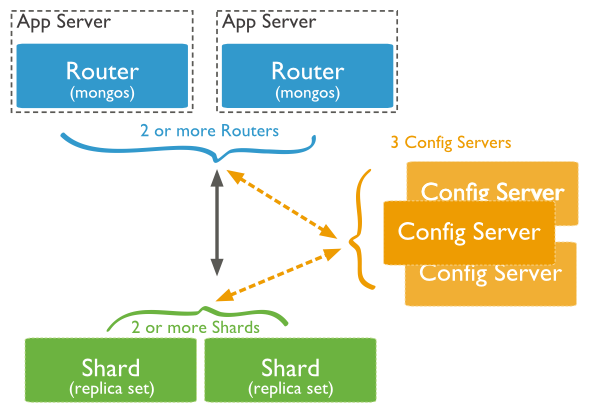
This diagram has mainly 3 components tied to it:
Shards – Shards are used to store information. They offer high availability as well as data consistency. Each shard in a production environment is a separate replica set.
Config Servers – Config servers are where the cluster’s metadata is stored. This information includes a mapping of the cluster’s data set to the shards. This metadata is used by the query router to direct operations to specific shards. Sharded clusters in production have exactly three config servers.
Query Routers – Query routers are essentially mongo instances that interact with client applications and route operations to the appropriate shard. The query router processes and routes operations to shards before returning results to clients.
A sharded cluster can have multiple query routers to distribute client request load. A client sends queries to a single query router. A sharded cluster will typically have a large number of query routers.
Replication in MongoDB
A replica set is a collection of mongod instances that share the same data set. A replica set consists of several data-bearing nodes and, if present, one arbiter node.
One and only one member of the data-bearing nodes is designated as the primary node, while the remaining nodes are designated as secondary nodes.
All write operations are routed to the primary node. A replica set can only have one primary capable of confirming writes with { w: “majority” } write concern; however, in some cases, another mongod instance may mistakenly believe it is also primary.
All changes to its data sets are recorded in the primary’s operation log or oplog.
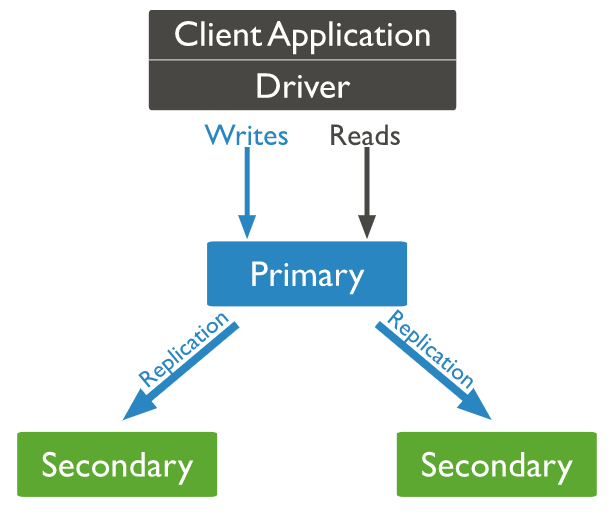
The secondaries replicate the primary’s oplog and apply the operations to their data sets in such a way that the data sets of the secondaries match the data set of the primary. If the primary is unable to be held, an eligible secondary will hold an election to determine who will serve as the new primary.
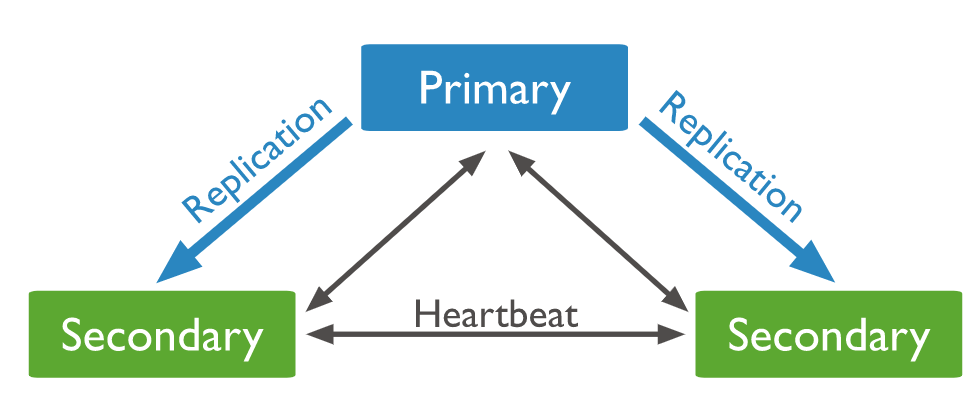
What is a Replica Set in MongoDB?
In MongoDB, a replica set is a collection of mongod processes that share the same data set. Replica sets provide redundancy and high availability, and they serve as the foundation for all production deployments.
Well, what if the system found a delay or an error occurred during the communication of information? This is taken care of by an automatic failover system. Let us learn about automatic failover in the next section.
Automatic Failover Systems
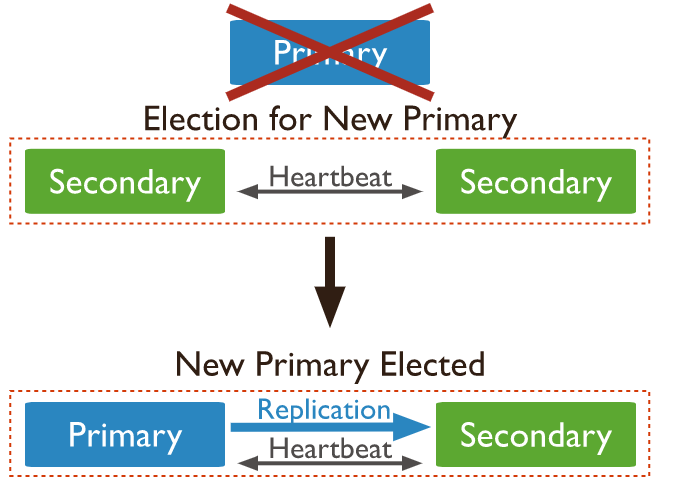
When a primary fails to communicate with the other members of the set for more than the electionTimeoutMillis period (10 seconds by default), eligible secondary calls for an election to nominate itself as the new primary. The cluster tries to finish the election of a new primary and return to normal operations.
Until the election is successfully completed, the replica set cannot process write operations. If read queries are configured to run on secondary servers while the primary is offline, the replica set can continue to serve them.
Factors such as network latency can increase the time it takes for replica set elections to complete, reducing the amount of time your cluster can operate without a primary. These variables are determined by the architecture of your cluster.
Very well, there goes a lot of operations happening at this point. With this, we have covered most of the sharding in MongoDB.
Noteworthy References
https://docs.mongodb.com/manual/replication/





