
New to Rust? Grab our free Rust for Beginners eBook Get it free →
Scrape Websites and Store Data in the Cloud with NodeJS

Crawling and scraping content is a complicated task. With so many tools and frameworks available, it’s a somewhat confusing and time-consuming task to do a trial and error with each framework to choose the one your project needs.
To solve such issues, ProxyCrawl provides you a service to crawl, scrape and store content on the cloud without maintaining any infrastructure. The crawling is done via proxy servers so there is complete anonymity. ProxyCrawl successfully crawls sites such as Amazon, Facebook, LinkedIn, etc.
We have already covered a tutorial featuring ProxyCrawl to crawl sites. You can check out this tutorial to learn more.
In this article, we are going to cover the new features provided by the ProxyCrawl which is a brand new Crawler and storage feature.
ProxyCrawl Crawler
While ProxyCrawl already provides crawling API best suited for developers, they have come up with a new product that is best suited for large-scale data gathering for your business.
You can crawl data in bulk without managing infrastructure, proxies, captchas, blocks, etc.
You can provide your own callback to the crawler and ProxyCrawl will push the crawled result to your callback. You can also use the storage provided by the ProxyCrawl to store results.
ProxyCrawl Storage
Generally, developers store the crawled content in the database or cloud storage such as S3, Azure, etc.
ProxyCrawl provides an alternative. You can crawl, scrape and store the content in the cloud storage provided by the ProxyCrawl.
ProxyCrawl handles the scaling and backup so you don’t have to worry about managing the infrastructure anymore.
You can sign up and try this for free for 10000 documents per month.
Enough talking, let’s give these products a try and see how it turns out.
Creating a Crawler
Create an account on ProxyCrawl and choose Crawler from the menu.
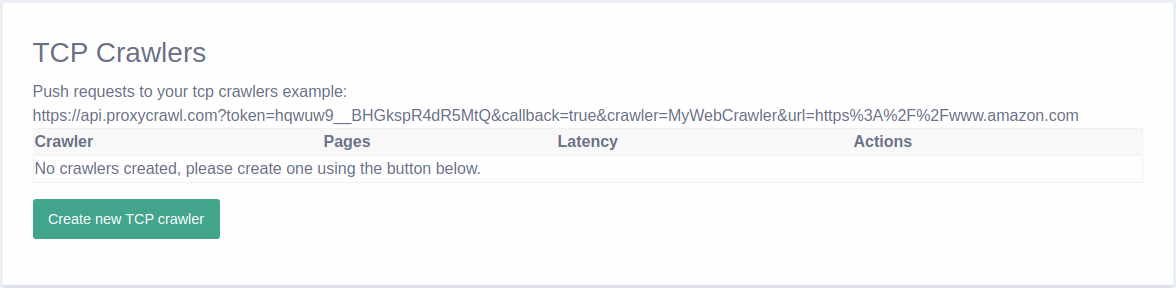
Then, go to the Crawlers tab and create a new TCP crawler.
Now, give it a proper name and choose the ProxyCrawl storage in the callback URL section.
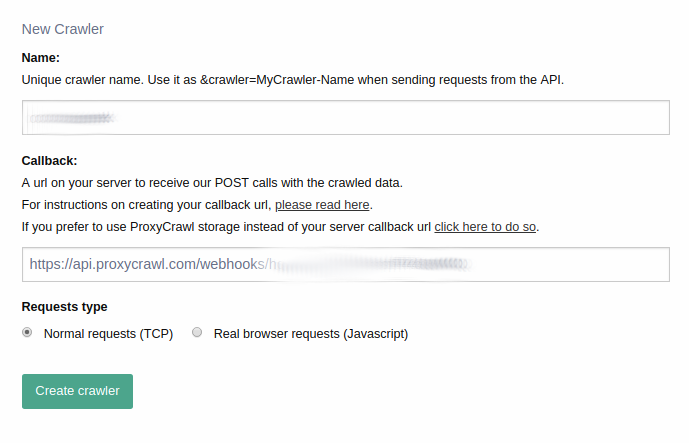
You can provide your own callback here as well. Now copy the crawler URL and let’s code a simple script to handle our API calls.
Here is the code in Node.js to make a call to our crawler.
First, install the dependency using the following command.
npm install request
Then, copy-paste this code, make sure to replace the token and crawler name. You can change the URL too.
const request = require('request');
const token = 'Your token';
const crawlerName = 'your crawler name';
const options = {
'method': 'GET',
'url': `https://api.proxycrawl.com?token=${token}&callback=true&crawler=${crawler}&url=https%3A%2F%2Fwww.amazon.com`,
'headers': {}
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});
Upon running the code, you should receive the output with request id in the response.
Once you receive the output, you can go ahead and check in the storage whether we got the scraped content or not.
From the menu, choose the storage product. You should see the request you made in the left tab.
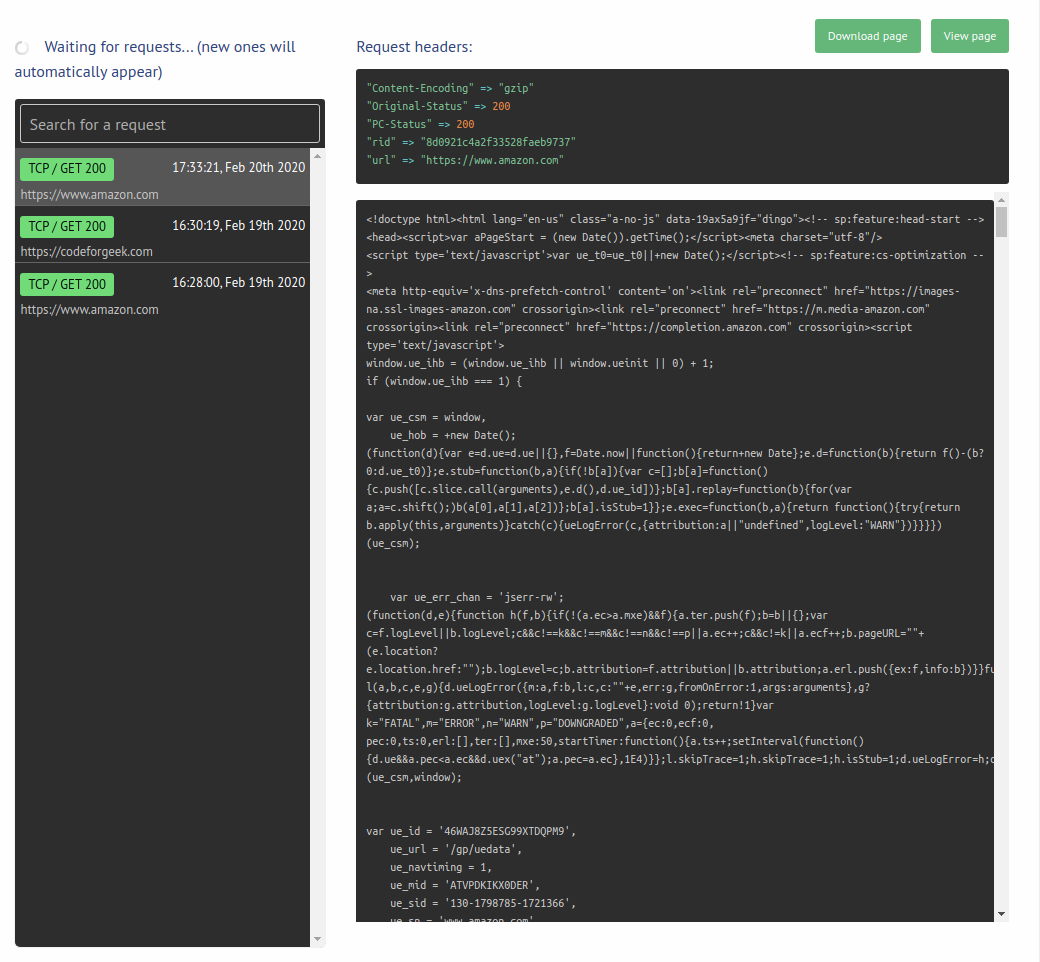
You can also use the GET API’s to retrieve the scraped content from the storage. Here is a sample codebase to do the same.
const request = require('request');
const token = 'copy/paste your token';
const rid = 'copy/paste the rid you received above';
const options = {
'method': 'GET',
'url': `https://api.proxycrawl.com/storage?token=${token}&rid=${rid}`,
};
request(options, function (error, response) {
if (error) throw new Error(error);
console.log(response.body);
});
Run this code and you should receive the parsed HTML content in the response.
You can also create your callback URL and pass it to the Crawler. Your callback URL must be publicly accessible and should accept POST requests.
You can ask the data either in HTML or JSON format from the crawler. Once your callback receives the request, it should respond with status code 200, 201 or 204 without content within 200 ms.
Conclusion
ProxyCrawl makes it really easy to crawl and scrape content. With it’s new cloud storage feature, it’s now even easier for developers to visit the scraped content as many times as they want without doing a scrape call again and again. The new Crawler supporting custom callback function is great for companies who want to use the crawling API but receive data in their infrastructure.





