
New to Rust? Grab our free Rust for Beginners eBook Get it free →
How Cross Validation Works in Data Products
In today’s world, companies attach the most importance to digital transformation in order to survive in a competitive environment. Using data to provide insights and forecasts for the future plays a crucial role in helping businesses to make healthy data-driven decisions. At this point, it would not be wrong to define data as today’s gold. Therefore, it is clearly seen that most of the investments are made in this field and we can also figure out this with the number of businesses that act based on data analytics.
However, this transition may cause some negative situations. Building end-to-end applications with data to generate core insights and key findings may be time-consuming or high cost depending on the choice when designing data pipelines.
Designing and building end-to-end machine learning applications are also called data products in terms of data science. In this article, we will focus on what are data products, why should we use them in our production environment, and the working logic of cross-validation in data products.
What are Data Products?
In the data analytics domain, we can separate all processes into three phases which are data engineering, reporting, and machine learning. Data engineering consists of ingesting raw data from a variety of sources into a data lake or data warehouse, executing ETL (extract, transform and load) jobs in raw data, and inserting this processed data into any kind of analytical database to feed machine learning or reporting phase with aggregated data.
In the reporting phase, aggregated data should be visualized effectively via any business intelligence tool to find key insights and make better data-driven decisions.
On the other hand, the machine-learning phase mainly involves extracting new features from aggregated data, designing the right hypothesis about the business problem, building a successful machine-learning model by maximizing the accuracy of the predictions, deploying it to the production environment, and monitoring the pipeline to make sure about data quality and workflow.
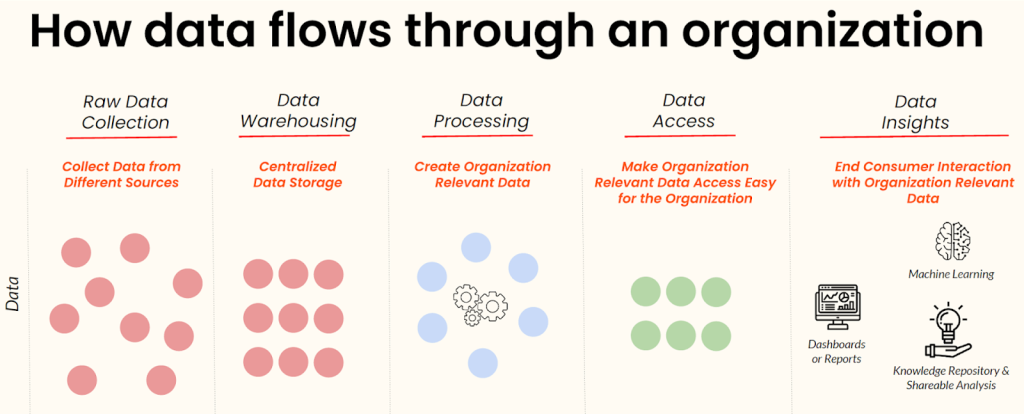
In summary, any software service or tool that builds a pipeline from ingesting data to visualization of data or machine learning phase can be called a data product.
Why Should We Use Data Products?
Data teams apply the process of data maintenance, writing extract-transform-load (ETL) jobs, designing hypotheses for better machine learning models by analyzing data, and deployment of a new version of the model many times in their daily work and it can be challenging and time-consuming to fix the faced problems. You also need to make sure about the consistency, reliability, and quality of the data when doing these routine processes.
Right at this point, data products offer to manage the whole process successfully by automatizing, monitoring, and debugging end-to-end pipelines. They make it easier to maintain the system and save most of your time. Besides these advantages, data products can give raw data, processed-aggregated data, data as a machine learning service, and data as insight outputs.
What Is Cross Validation in Data Products?
In the machine learning pipelines, one of the most common difficulties is data bias which can cause dramatic failure in the success of model predictions. The resultant machine-learning model is chosen after the train-test split process which is the evaluation technique to find the best-performed model for the production environment. Many companies and organizations have a huge dataset and this dataset should be homogeneously split into train-test parts to prevent the biasing problem.
Cross-validation in machine learning is a statistical technique to evaluate the average estimation performance of many of the independent machine learning models by splitting different parts of the dataset into test sides in each prediction. It means that you can know detailed performance statistics of the trained models by getting the minimum, maximum, and average estimation performances.
Thanks to this statistical approach, data teams can get important insights into the limitation of the final model that will be deployed into production as a service. In addition to that, the team gains the ability to give healthy feedback & outcomes to clients and stakeholders.
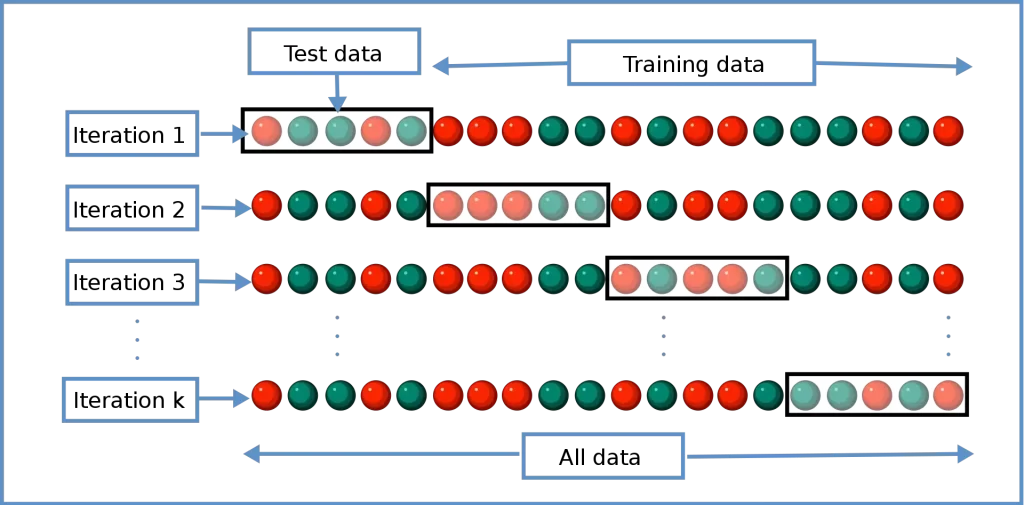
How Cross-Validation Works in Data Products
There are mainly two subgroups of cross-validation in terms of working logic which are exhaustive and non-exhaustive approaches. In the exhaustive approach, the data product evaluates all possible pairs by splitting data into train and tests. On the other hand, the non-exhaustive approach does not calculate all ways of the partitioning of train-test sets. We can list five common types of cross-validation which are the holdout method, K-fold cross-validation, stratified K-fold cross-validation, leave-p-out cross-validation, and leave-one-out cross-validation.
In the general working logic of cross-validation, data will be split as train and test sets in a certain proportion which is %80-%20 that comes from the Pareto principle. After the split process, data will be modeled using a train set and evaluated the performance of it with a test set. In every iteration, a different combination of data points will be used as a test set for prediction. Finally, the average accuracy will be evaluated from each iteration’s result and the best-performed model can be chosen in this way for the production environment.
The process as explained above, a pipeline can be too complex according to the number of iterations and it may take too long to work. This means that there should be enough computational sources to execute all systems. Therefore, we need to integrate data products into our pipelines.
Conclusion
Most organizations have been continuing to develop data-centric projects to feed business decisions and cross-validation will continue to be part of this system. I hope you found this article informative and that it helped you figure out what is cross validation and how it works in data products.





